Tartalomjegyzék
1. Bevezető
A sERPa Interfész funkció egy API készítő API, amivel a működési mód függvényében API-kat, illetve API klienseket definiálhatunk. Szolgáltató: "sERPa" működési módban a sERPa biztosít API-t a külső rendszernek, míg Szolgáltató: "Külső rendszer" esetén a sERPa veszi igénybe a külső API szolgáltatásait.
Ebben a topicban a "sERPa, mint szolgáltató" működési módú interfészeket, azaz a sERPa API-kat tárgyaljuk.

Általában egy programnak egy API-ja van, amelyen keresztül elérhető a program összes publikus adata, funkciója. Ezzel szemben a sERPában minden interfész egy különálló API, így minden partnernek saját, testre szabott API-t készíthetünk, amelyen keresztül csak a számára engedélyezett adatokhoz és funkciókhoz férhet hozzá. Természetesen annak sincs akadálya, hogy csak egy, általános API-t definiáljunk, és mindenki azt használja. A lényeg az, hogy az API-kat mi definiálhatjuk, szabadon.
A sERPa API-n keresztül üzleti adatokat továbbítunk, ezért csak titkosított (https) protokoll használható. A https protokollt a webszerverben kell beállítani.
2. Swagger
A sERPa minden API-hoz automatikusan készít egy saját OpenAPI dokumentációt, azaz egy swagger.json fájlt, valamit egy swagger oldalt, amelyen keresztül az adott API felhasználói megismerhetik az API lehetőségeit, illetve kipróbálhatják az API-t. Minden swagger oldal a saját API-ján belül érhető el:

Az URL első része ("serpaapiteszt.progen.hu") a sERPaAPI webalkalmazásunk címe, ezt telepítéskor határoztuk meg. A második rész ("sampleapi") az API egyedi neve, amelyet a sERPában az URL mezőben definiálhatunk:

Ha új interfészt hozunk létre, vagy megváltoztatjuk az URL-t, csak akkor lesz Swagger oldalunk, ha újraindítjuk a sERPaAPI webalkalmazást.
Az URL mezőben csak az API egyedi nevét kell megadni, nem a teljes URL-t. Az API egyedi neve (a fenti URL mező) nem tartalmazhat "/" jelet.
Az URL harmadik része fix, az API-n belül mindig a "swagger/index.html" URL-en találjuk a Swagger oldalt.
A Swagger oldalról a fejléc alatti link segítségével letölthetjük a swagger.json fájlt. A fájl sok mindenre jó lehet, például automatikusan generálhatunk vele API klienst.
Ha több API-nk van, mindegyiknek saját Swagger oldala és swagger.json fájlja van:
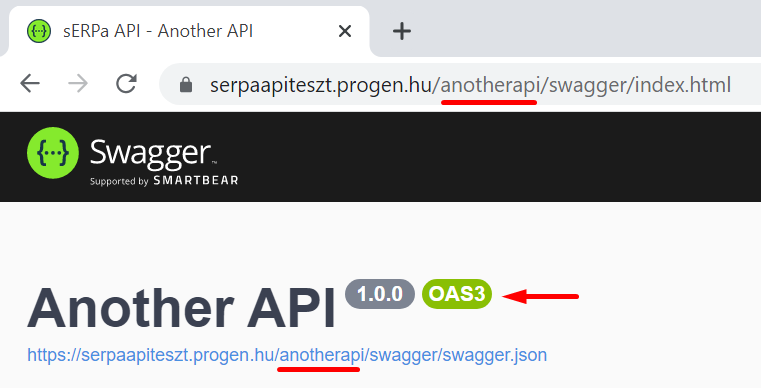
A Swagger dokumentáció az OpenAPI v3.0.0 szabványnak megfelelően készül.
Fontos tudni, hogy ha az Interfész definícióban valamit módosítunk, a Swagger oldal azonnal (a következő betöltésekor) frissül, de a sERPaAPI webalkalmazás csak 5 percenként frissíti az interfész adatait, ezért ha az Interfész definíció Általános fülén valamit módosítunk, akkor annak csak 5 perc múlva lesz hatása. Ha gyorsítani szeretnénk a folyamatot, a változtatások után indítsuk újra a sERPaAPI webalkalmazást.
3. Fejléc
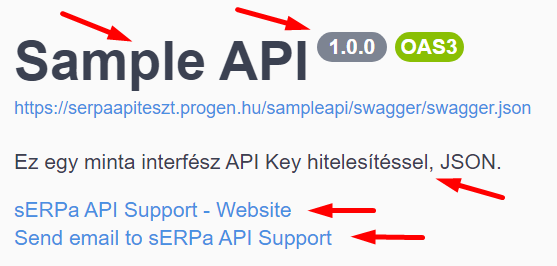
A fejlécben megjelenik az API neve, verziója, leírása, valamint két link:
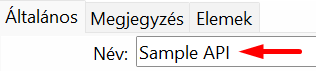
A nevet és a leírást a sERPában adhatjuk meg:

A sERPában a leírást formázhatjuk, de a Swagger oldalon egyszerű, formázatlan szövegként fog megjelenni.
3.1. Verziószámozás

Az API verziójának semmi köze nincs a sERPa verziójához, a kettő teljesen független egymástól.
A Verziót lehetőleg a Szemantikus Verziószámozás szerint adjuk meg.
•Az első szám a főverziószám. Ezt akkor léptessük, ha olyan változás van az API-ban, amitől elveszítjük a kompatibilitást a korábbi verzióval (breaking changes), például teljesen megváltozik egy API hívás eredménye.
•A második szám az alverziószám. Ezt akkor változtassuk, ha csak olyan változás van az API-ban, ami megőrzi a kompatibilitást, például új API hívást készítettünk, vagy kibővítjük egy API hívás eredményét, de a régi mezők változatlanul elérhetők.
•A harmadik szám a hibajavítás verziószáma. Ezt akkor léptessük, ha kompatibilis hibajavításokat végeztünk.
A helyes verziószámozás rendkívül lényeges az API-k esetében. Miután kiadtunk egy API-t, nem tudhatjuk, hogy azt hányan használják a nagyvilágban. Ha az API-t megváltoztatjuk, de a verziószámot nem, akkor az API felhasználói nem értesülnek a változásról, nem fog működni a programjuk.
A sERPaAPI esetében ez másképp van, mert mindenkinek testre szabott API-t készíthetünk, de azért figyeljünk oda a verziószámozásra, értesítsük a partnert az API megváltozásáról.
A legtöbb helyen az API "kőbe van vésve", a kiadása után csak kompatibilis változtatásokat végeznek bennük. A főverziószámot belerakják az URL-be, pl. "sampleapiv1", vagy "sampleapi/v1". Ha a kompatibilitás elvesztésével járó változtatást kell végezni, akkor készítenek egy teljesen új API-t, új URL-en pl. "sampleapiv2", vagy "sampleapi/v2", a régit pedig meghagyják érintetlenül. Így a régi API-hoz megírt programok továbbra is zavartalanul működhetnek, az új API-t használók pedig kihasználhatják az új lehetőségeket.
A sERPaAPI-ban a "sampleapiv1" forma használható, a "sampleapi/v1" nem, mert az interfész nevében nem lehet "/" jel.
3.2. Linkek
A fejléc alatt található két link közül az első a sERPa súgó Interfész oldalára visz, a második segítségével pedig a PROGEN support-nak küldhetünk e-mailt. A linkek szövege és címe nem változtatható meg, a linkek nem szedhetők le.
4. Protokoll, adatformátum

A Protokoll-ban jelenleg csak a REST-et választhatjuk.
A Protokoll megadásának semmi jelentősége nincs, hiszen az egész API-t mi definiáljuk. Ha szeretnénk, akkor a REST protokollnak megfelelően definiáljuk az interfész elemeit (a végpontokat), ha távoli eljáráshívásokat szeretnénk, akkor definiálhatunk csupa POST kérést. Minden tőlünk függ. Ezért aztán az itt megadott Protokollnak semmilyen hatása nincs semmire, a mező felesleges.
XML és JSON adatformátum közül választhatunk. A JSON adatformátum használata ajánlott, mert azt minden funkció 100%-ban támogatja. XML adatformátum esetén az Adatátadás sERPának típusú elemek nem használhatók, és a mezőadatok csak nem szabványos módon érhetők el.
Mindkét adatformátum esetén a bemenő és kimenő adatok (a request és response body) UTF-8 kódolásúak.
5. Hitelesítés
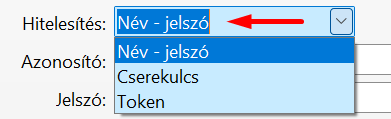
Az API csak hitelesített felhasználó kéréseit fogadja el, ezért, mielőtt bármelyik hívást használni szeretnénk, hitelesíteni kell magunkat. A hitelesítés módját a sERPában adhatjuk meg:
A Swagger-ben a fejléc alatt jobb oldalon található az Authorize gomb. Az első hívás előtt itt adhatjuk meg a hitelesítő adatokat. Használhatjuk a végpontok végén található lakat ikont is, mindkettő ugyanoda visz:
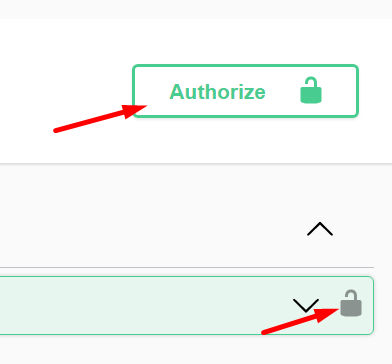
5.1. Név - jelszó (Basic) hitelesítés
A sERPában adjuk meg az Azonosítót és a Jelszót:
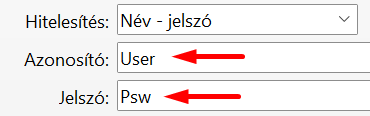
Az Azonosító és a Jelszó csak ASCII karaktereket tartalmazhat, a ":" nem megengedett.
A Swagger-ben adjuk meg a nevet, jelszót, amit a sERPában beállítottunk, nyomjuk meg az Authorize gombot, majd zárjuk be az ablakot:

A hitelesítő adatok megadásakor nem történik API hívás, csak a Swagger feljegyzi az adatokat, és hozzáfűzi azokat az elkövetkező kérések fejlécéhez:

A hitelesítő adatokat egy Authorization fejléc bejegyzésben kell átadni, melynek értéke: "Basic <credentials>", ahol "<credentials>" a sERPában megadott Azonosító és Jelszó, kettősponttal elválasztva, Base64 kódolásban.
5.2. Cserekulcs (API Key) hitelesítés
A sERPában adjuk meg a Cserekulcsot:

A Cserekulcs mezőben csak ASCII karakterek adhatók meg. Jellemzően egy GUID-ot szoktak használni, ami generálható pl. itt.
A Swagger-ben adjuk meg a cserekulcsot, amit a sERPában beállítottunk, nyomjuk meg az Authorize gombot, majd zárjuk be az ablakot:
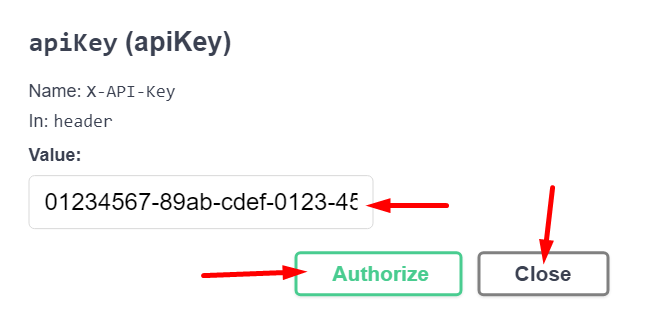
A cserekulcs megadásakor sem történik API hívás, csak a Swagger feljegyzi azt, és hozzáfűzi az elkövetkező kérések fejlécéhez:

A Cserekulcsot egy "X-API-Key" fejléc bejegyzésben kell átadni, melynek értéke a sERPában megadott Cserekulcs.
5.3. Token (Bearer) hitelesítés
A sERPában adjuk meg az Azonosítót, a Jelszót, valamint egy Hitelesítés URL-t:
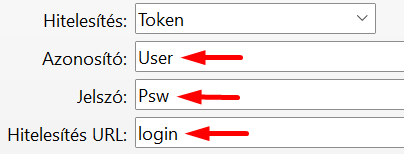
Az Azonosító, Jelszó mezőkben tetszőleges karaktereket használhatunk. A Hitelesítés URL-ben adhatjuk meg azt az API-n belüli végpontot, melynek meghívásával hitelesíthetjük magunkat, megszerezhetjük az API használatához szükséges tokent.
A hitelesítő Token megszerzéséhez egy POST hívást kell intéznünk a sERPában megadott Hitelesítés URL-re. A hitelesítés hívás mindig legfelülre kerül a Swagger-ben, hogy könnyedén elérjük:
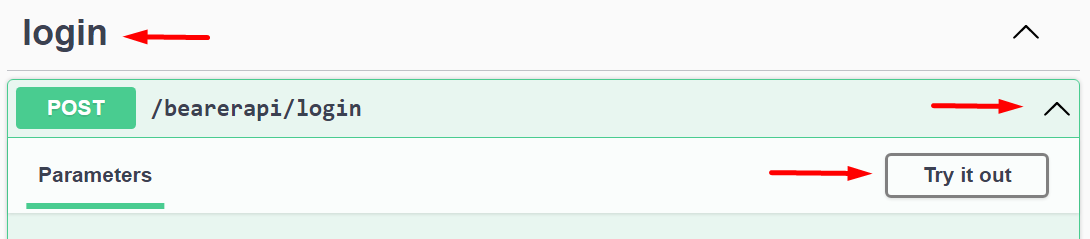
Figyelmes olvasók felfedezhetik, hogy a login hívás jobb sarkában nincs lakat. Ez azt jelenti, hogy anonim hívás, autentikáció nélkül is meghívhatjuk. Más nem is lehetne, hiszen ezzel jelentkezünk be.
Nyissuk le a végpontot, nyomjuk meg a Try it out gombot, adjuk meg az Azonosítót és a Jelszót, majd nyomjuk meg az Execute gombot:
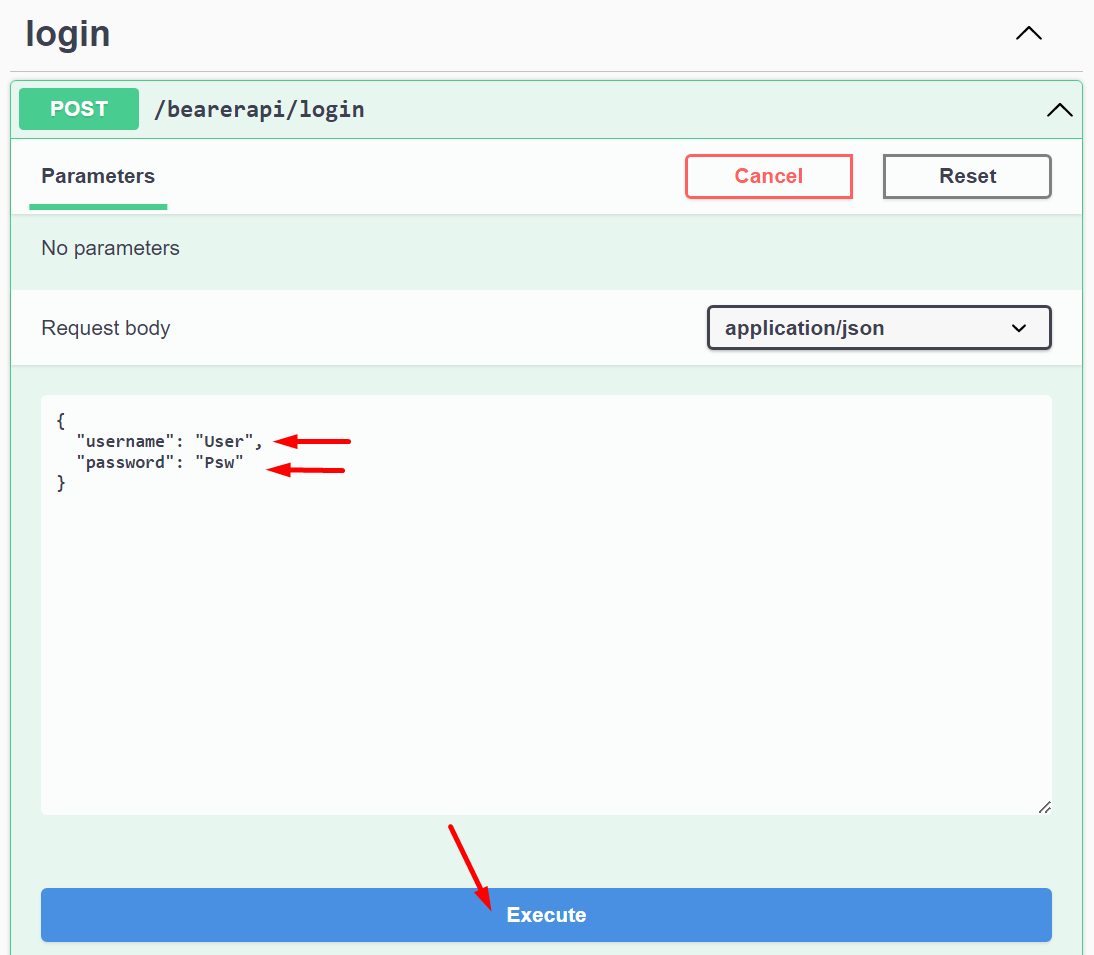
A Swagger által összeállított hívásban láthatjuk, hogy a név, jelszót a request body-ban kell átadni:
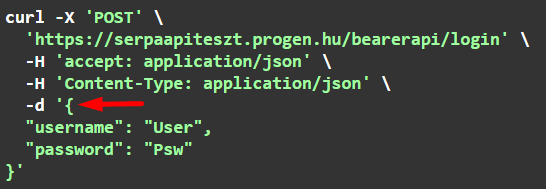
A válaszban van a hozzáférési token:

A token kimásolására nem használható a Másolás gomb, mert az az egész eredményt kimásolja, nekünk meg csak a token (a macskakörmök közötti érték) kell. Ha mégis a gombbal másoljuk, akkor előbb másoljuk be valahova, mondjuk a Jegyzettömbbe, jelöljük ki a macskakörmök közötti részt, és csak azt másoljuk vissza a Swagger-be.
Menjünk az oldal tetejére, nyomjuk meg az Authorize gombot, és adjuk meg a tokent:
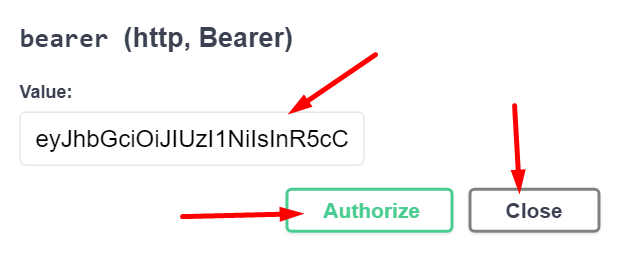
A tokent a Swagger hozzáfűzi minden kérés fejlécéhez:

Ha az API XML adatformátumot használ, a login body-ban a hitelesítő adatokat XML-ben kell megadni:
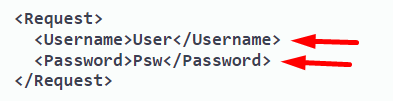
A kérésben is XML-t adunk át:
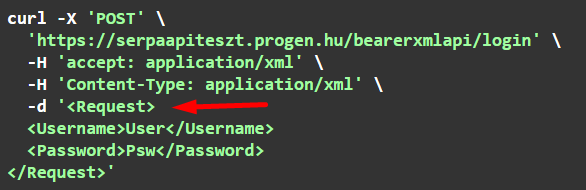
A választ is XML-ben kapjuk:

Az adatformátumtól függetlenül a hívások fejlécébe mindig ugyanúgy kerülnek be a hitelesítő adatok.
A sERPa API JSON Web Tokent (JWT) használ. A JWT Base64 enkódolt, és egyszerűen visszafejthető a jwt.io oldal segítségével:
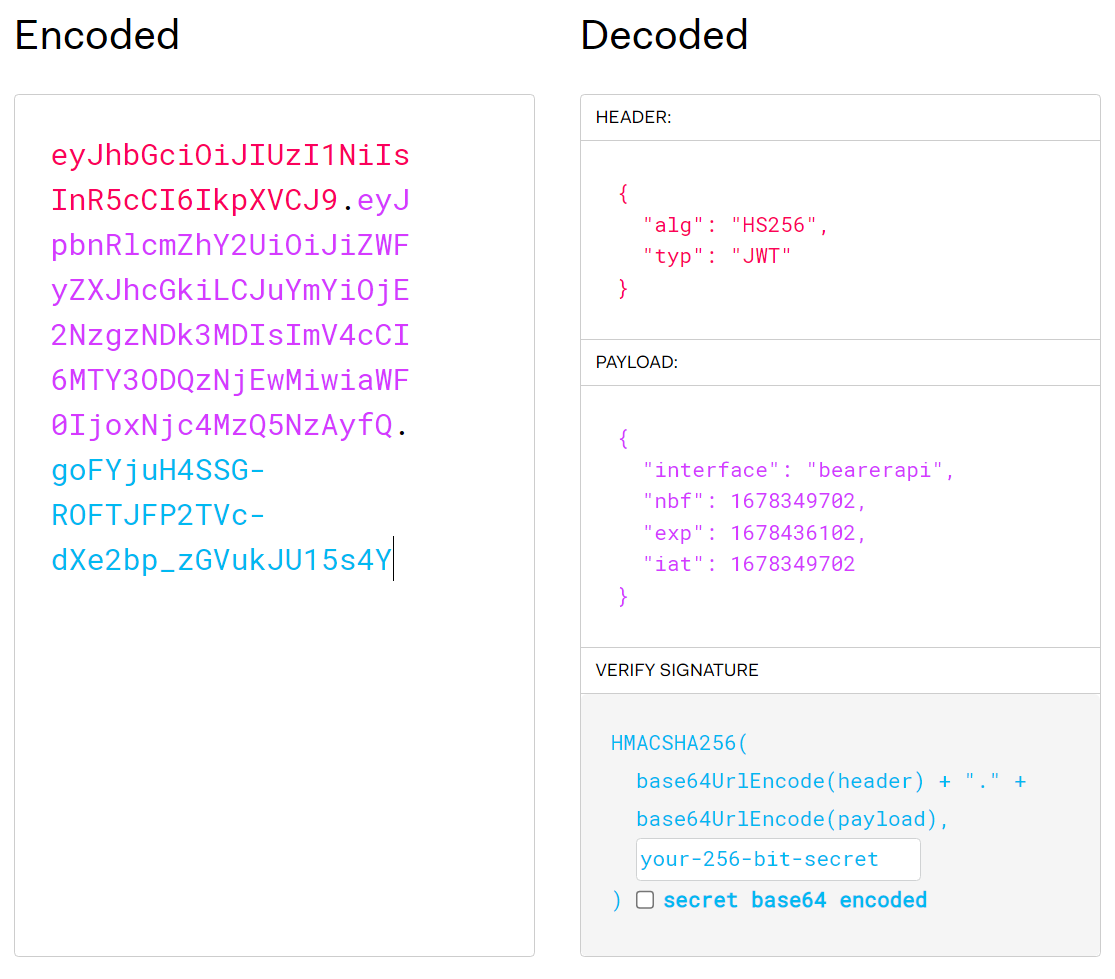
A JWT hitelességét az aláírás igazolja. Az aláírás egy kulccsal titkosítva van. A kulcs birtokában ellenőrizhetjük a JWT aláírását is. A kulcsot a sERPaAPI webalkalmazás telepítésekor kell megadni az appsettings.json fájl JWT fejezetében. Az összes API-hoz ugyanaz a JWT kulcs tartozik. A JWT kulcsot soha, semmilyen körülmények között ne osszuk meg senkivel, mert a kulcs birtokában bárki generálhat hitelesnek tűnő JWT-t, amivel bármelyik API-hoz hozzáférhet.
6. Végpontok
Az API végpontokat az Interfész funkció Elemek fülén definiálhatjuk:
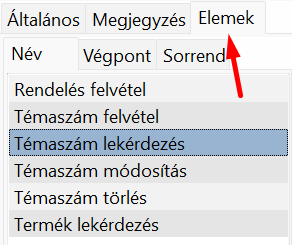
A végpontok kétféle típusúak lehetnek:

A részleteket lásd a Működési módok topicban.
A végpontok létrehozás, módosítás után azonnal megjelennek a Swagger-ben, kipróbálhatók, használhatók:
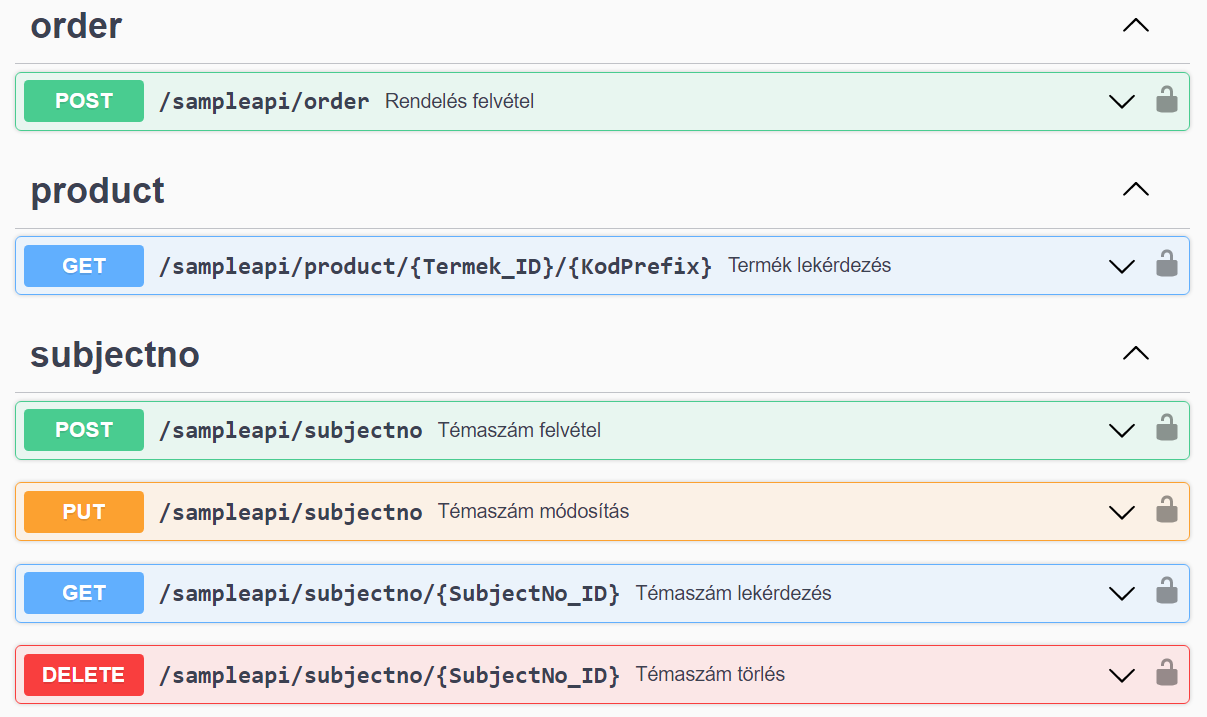
A Swagger-ben a végpontok entitások szerint csoportosítva vannak, az entitások ABC sorrendben jelennek meg, a végpontok a csoporton belül a teljes URL szerint vannak sorrendbe rakva, azonos URL esetén CRUD sorrendben jelennek meg (Create, Read, Update, Delete, azaz POST, GET, PUT, PATCH, DELETE).
A fenti példában a témaszám teljes REST CRUD interfészt valósít meg, a rendelés és termék pedig csak egy-egy végpontot.
6.1. A végpont alapadatai
A végpont alapadatait a sERPában adjuk meg:
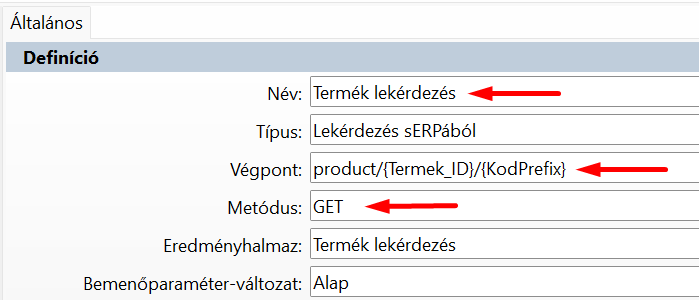

Ez így jelenik meg a Swagger-ben:
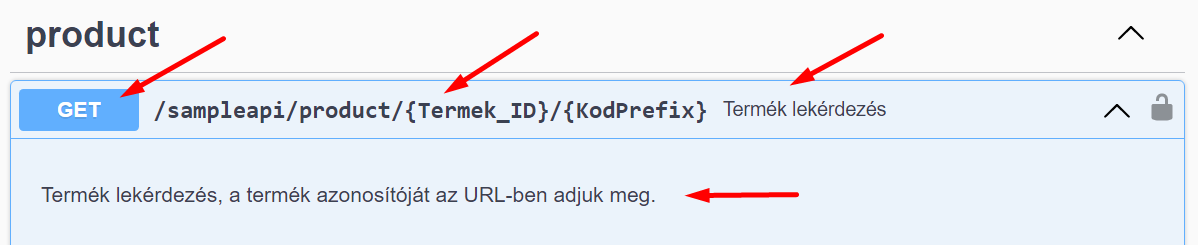
6.2. Metódus
A Metódust lehetőleg a REST ajánlása alapján válasszuk ki, mert ez a legelterjedtebb megoldás, az API felhasználói erre számítanak:
Lekérdezés sERPából esetén: GET. A POST-ot csak akkor válasszuk, ha a paramétereket a kérés body-jában szeretnénk átadni, mert a GET metódusnak nincs body-ja.
Adatátadás sERPának esetén:
Felvétel: POST
Módosítás: PUT vagy PATCH. A PUT való az entitás lecserélésére, a PATCH pedig az entitás néhány tulajdonságának megváltoztatására.
Törlés: DELETE
7. Paraméterek forrása
7.1. "Lekérdezés sERPából" típus esetén
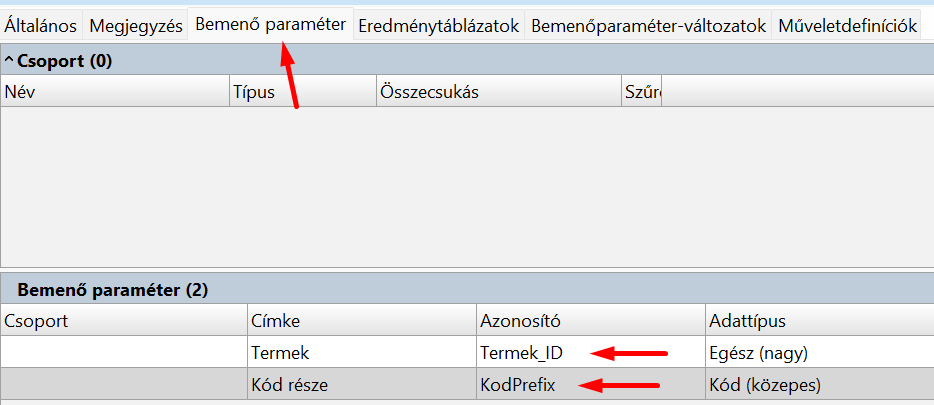
A végpont paraméterei a végponthoz tartozó Eredményhalmaz / Bemenőparaméter-változat Bemenő paraméterei lesznek:
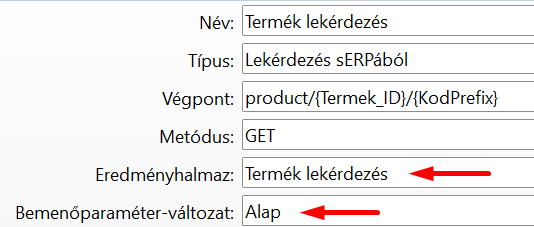
Az eredményhalmaz-lekérdezés bemenő paramétereit a Bemenő paraméter fülön találjuk:
7.2. "Adatátadás sERPának" típus esetén
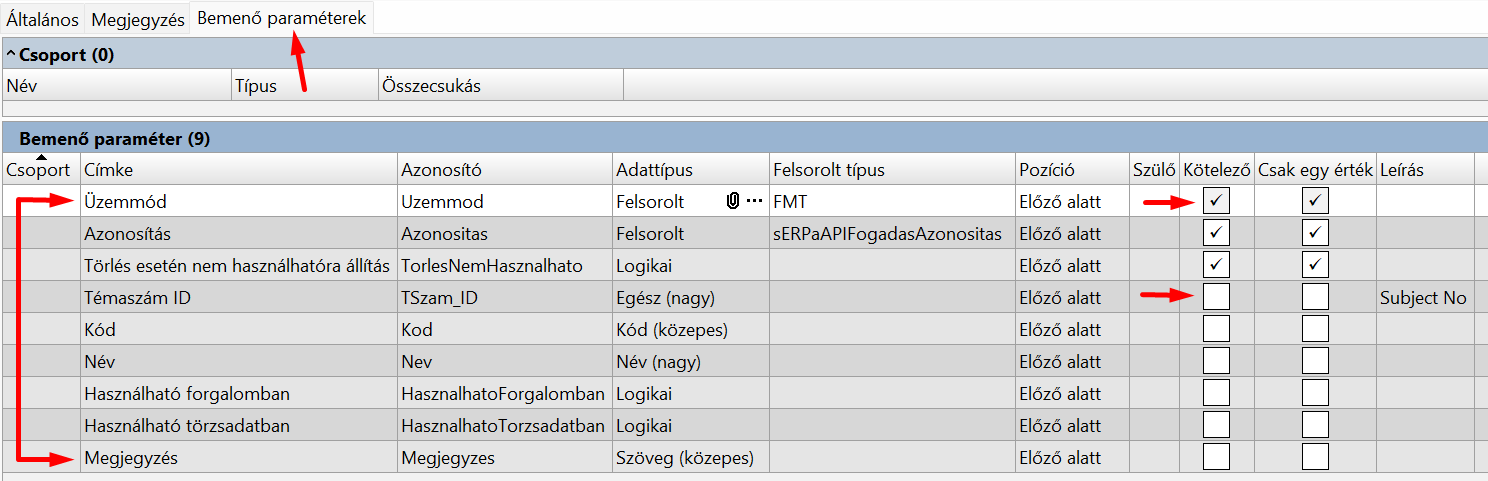
A végpont paraméterei a végponthoz tartozó Művelet Bemenő paramétereiből választhatók:

A Művelet bemenő paramétereit a Bemenő paraméterek fülön találjuk:
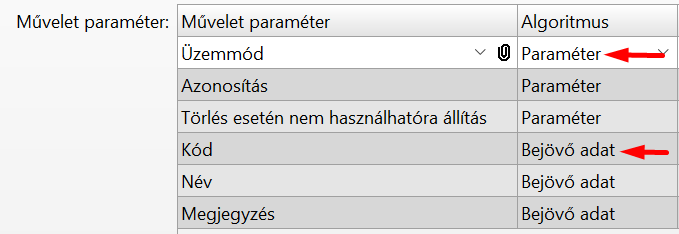
Az Interfész funkcióban a művelet paraméterei közül kiválogathatjuk, hogy melyeket szeretnénk a sERPában megadni ("Paraméter"), és melyek legyenek az API végpont paraméterei ("Bejövő adat"):
A "Paraméter" típusúaknak az Interfész funkció paraméter értékek fülén értéket kell adnunk:

8. Paraméterek megadása
A paraméterek megadásának 7 különböző módja lehetséges:
1.Path paraméterek "Lekérdezés sERPából" típus és GET metódus esetén
2.Query paraméterek "Lekérdezés sERPából" típus és GET metódus esetén
3.Body paraméterek "Lekérdezés sERPából" típus, POST metódus és JSON adatformátum esetén
4.Body paraméterek "Lekérdezés sERPából" típus, POST metódus és XML adatformátum esetén
5.Body paraméterek "Adatátadás sERPának" típus, POST, PUT, PATCH metódusok és JSON adatformátum esetén
6.Body paraméterek "Adatátadás sERPának" típus, POST, PUT, PATCH metódusok és XML adatformátum esetén
7.Path paraméterek "Adatátadás sERPának" típus és DELETE metódus esetén
8.1. Path paraméterek "Lekérdezés sERPából" típus és GET metódus esetén
Egy végponton belül a a Path és Query paramétereket nem lehet keverni. Az adott végpont összes paramétere vagy a path-ban van, vagy query paraméterekben.
Path paraméter létrehozásához a sERPában a Végpont path-jába egy elválasztó "/" után "{}"-ek közé írjuk be a paraméter Azonosítóját. Ezzel jelezzük a sERPa API-nak, hogy az adott végpontban path paramétereket használunk:

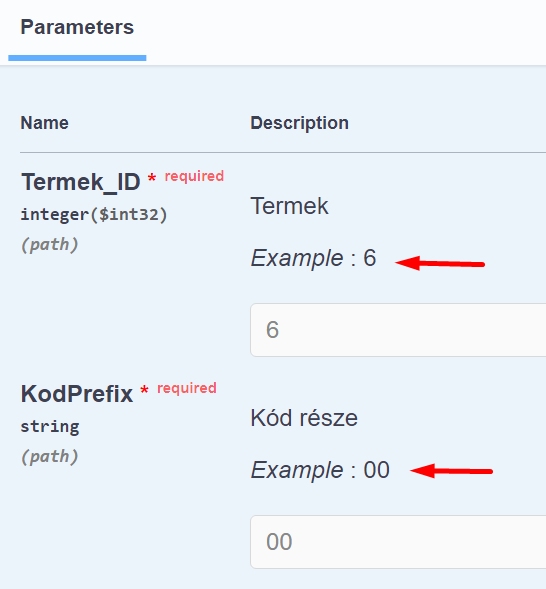
A sERPában egy lekérdezésnek (a lekérdezés mögött álló Eredményhalmaz-lekérdezésnek) általában több paramétere van. Ilyenkor több path paraméterünk lesz, melyeket a path-ban "/" karakterrel elválasztva adhatunk meg, ahogy azt a Termék lekérdezésben láthatjuk:
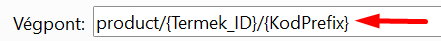
Ha Swagger-ben lenyitjuk a végpontot, láthatjuk a paramétereket:
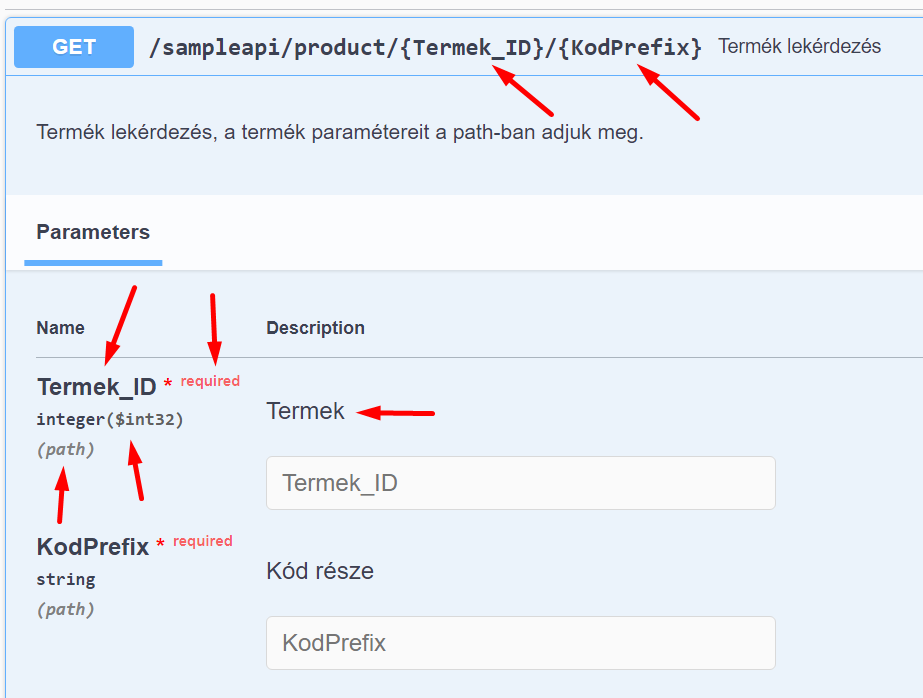
Látható, hogy path paramétereink vannak. A path paraméterek kötelezők.
Megjelenik a paraméter Azonosítója, Címkéje, a paraméter típusa, integer és number esetén a mérete, korlátos string esetén a maximális hossza, felsorolt típus esetén a használható értékek és jelentésük.
Híváskor mindkét paraméter szerepel a path-ban:

Ha nem írunk be minden paramétert a Végpont-ba:

akkor a hiányzó paraméterek nem fognak megjelenni a végpont paraméterei között, nem tudunk nekik híváskor értéket adni. Ez akkor lehet jó, ha a paraméter az Eredményhalmaz-lekérdezésben opcionális, vagy van alapértelmezett értéke, ilyenkor kihagyhatjuk:
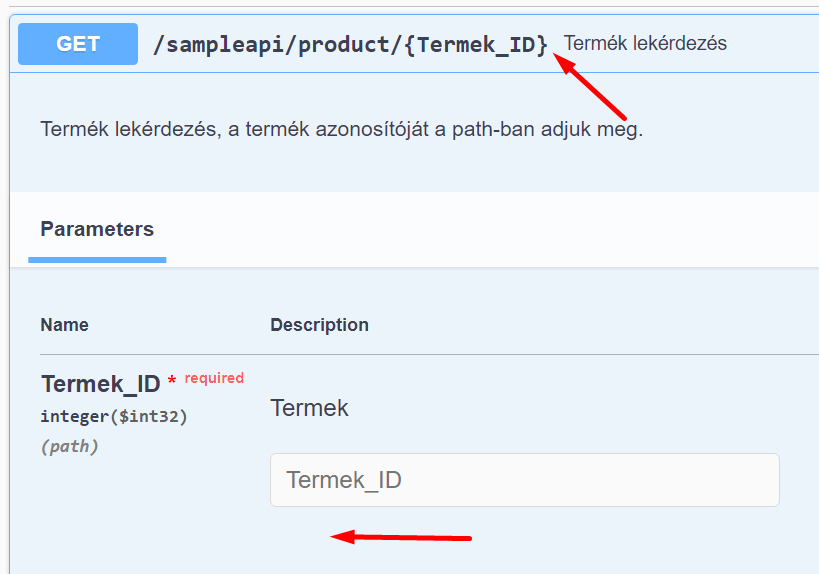
Híváskor csak a meglévő paraméterek szerepelnek a path-ban:

A karaktereket URL enkódolással kell a path-ba rakni:
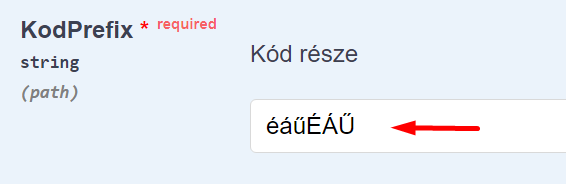

Több paraméter szerepeltetése a path-ban nagyon szokatlan megoldás, ezért lehetőleg ne használjuk.
Ha csak egy paraméterünk van, akkor ezt a megoldást célszerű használni. Például REST API esetén a végpont path-jában adjuk át az entitás ID-jét, ahogy azt a Témaszám lekérdezésben láthattuk.
Példa
A sERPa Interfész funkcióban összeállíthatunk egy példa hívást:

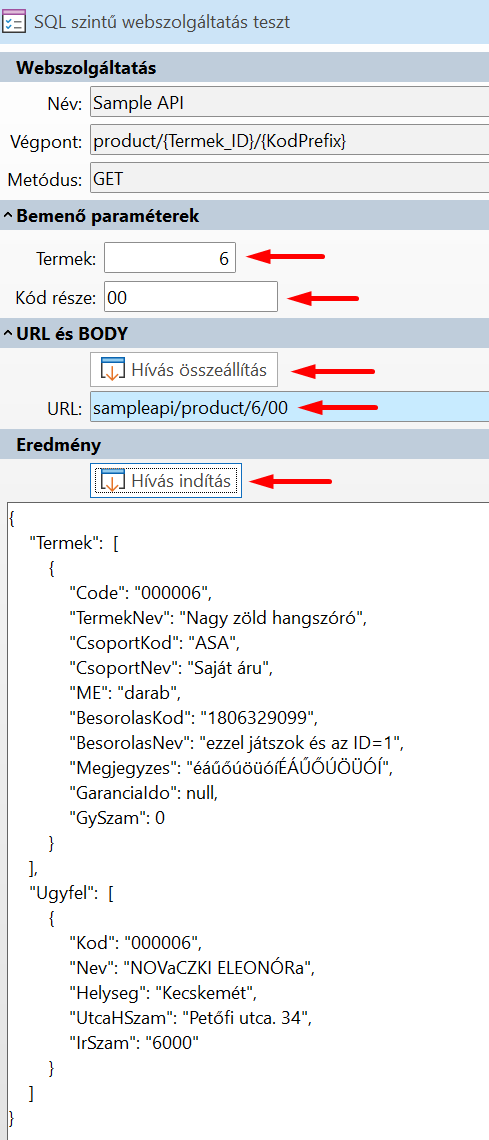
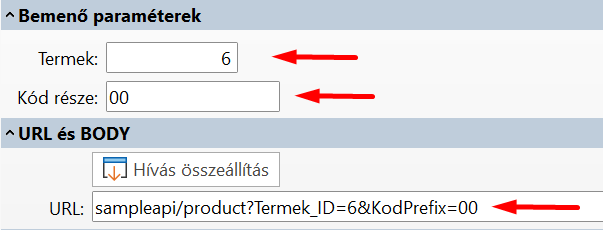
Megadhatjuk a Bemenő paramétereket, majd a Hívás összeállítás gomb megnyomásával a sERPa elkészít nekünk egy példa hívást. Láthatjuk, hogy path paramétereket készített.
A Hívás indítás gomb segítségével kipróbálhatjuk a hívást. Ha minden rendben, mentsük el példaként, majd zárjuk be az ablakot:
Az így összeállított példa kerül a Swagger-be:
Mindig készítsünk példát. Egyrészt a sERPában kipróbálhatjuk, hogy működik-e a hívás, másrészt az API használójának egy működő példával szolgálunk, ami segíti a végpont megértését.
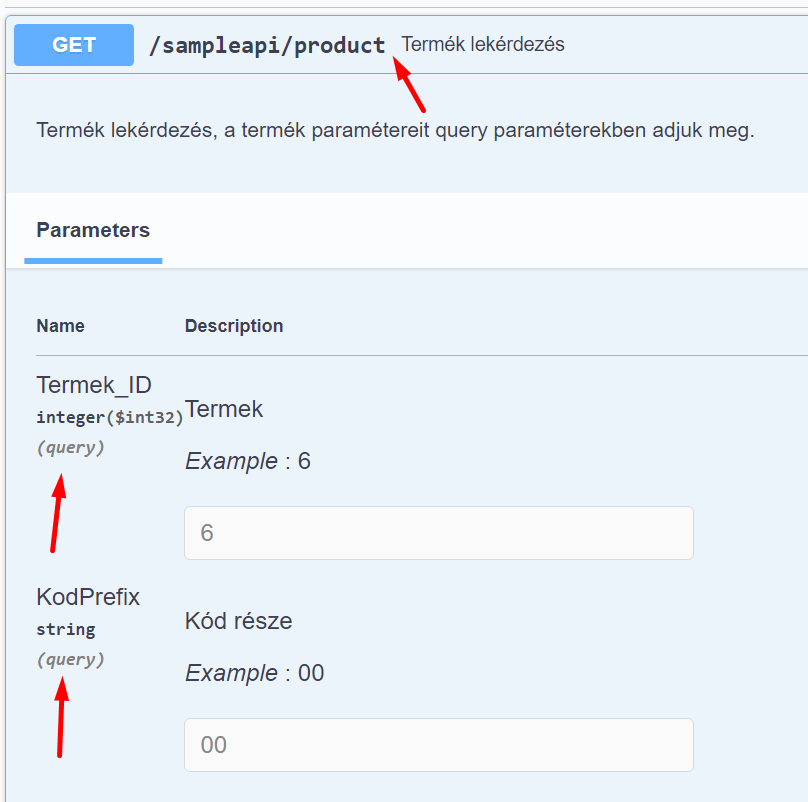
8.2. Query paraméterek "Lekérdezés sERPából" típus és GET metódus esetén
Ez a paraméterek alapértelmezett helye. Ha nem jelezzük, hogy path paraméterek legyenek, akkor query paraméterek lesznek:

A Kipróbálás gomb segítségével készítsünk példát:
A paraméterek így jelennek meg a Swagger-ben:
Híváskor szabványos query paraméterként kell átadni:

A query paraméterek nem kötelezők, az API hívásban a sorrendjük sem számít, ezért sokkal rugalmasabbak, mint a path paraméterek:


A karaktereket URL enkódolással kell a query paraméterekbe rakni:
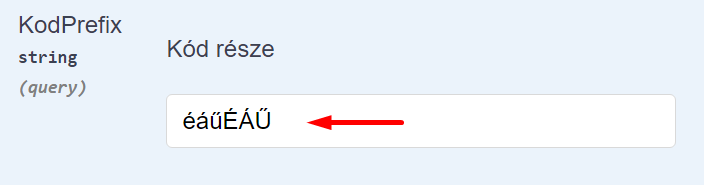

Ha egynél több paraméterünk van, használjunk query paramétereket.
8.3. Body paraméterek "Lekérdezés sERPából" típus, POST metódus és JSON adatformátum esetén
POST metódus esetén a paramétereket a request body-ban kell átadni:


Készítsünk példát, próbáljuk ki, mentsük el:
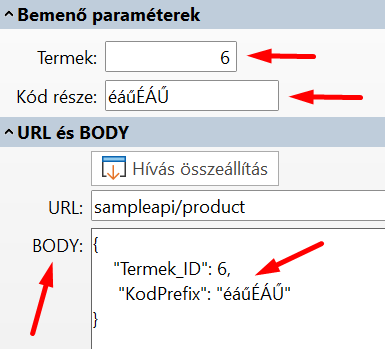
Ha nem készítünk példát, akkor a sERPa API készít egyet, amelynek a felépítése ugyanolyan lesz, mint az általunk készített példának, csak nem lesznek benne értelmes adatok.
A paramétereket egy UTF-8 kódolású JSON objektumban kell átadni:
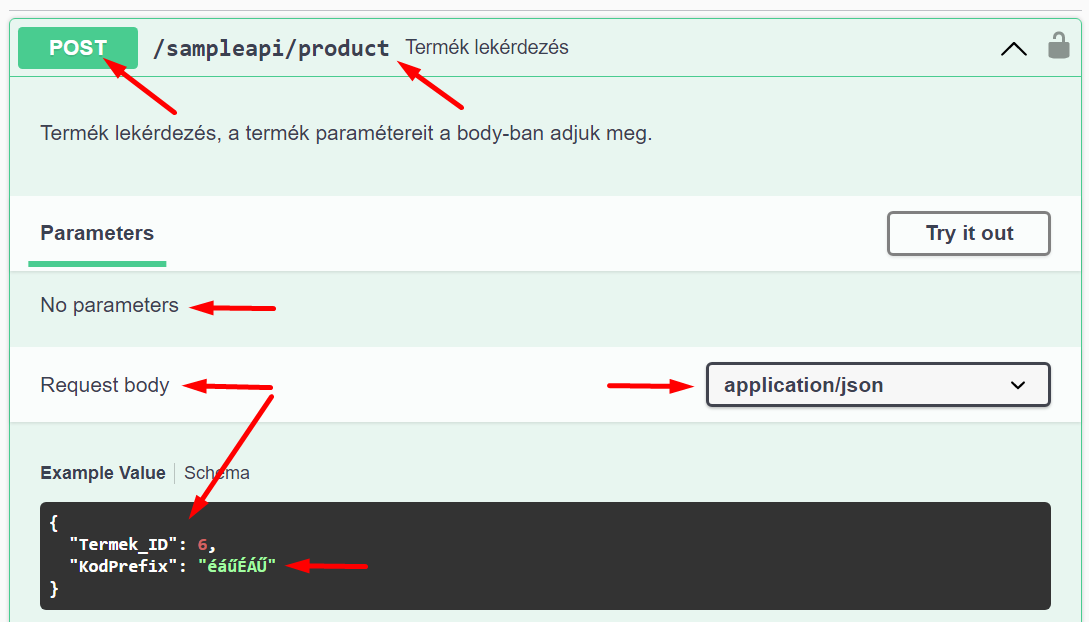
Az összes paraméter a gyökér objektum tulajdonsága, a paramétereknek nincs további belső struktúrája, nincsenek benne tömbök, gyermek objektumok, stb.
A JSON ajánlása szerint a tulajdonságok nevei "camelCase" formátumúak, tehát kisbetűvel kezdődnek. A sERPa API-ban a tulajdonságok nevei kisbetű-nagybetű híven követik a sERPa Eredményhalmaz-lekérdezés Bemenő Paraméter fülén, az Azonosító oszlopban megadott értékeket, ezért ha azt szeretnénk, hogy a tulajdonságok nevei kisbetűvel kezdődjenek, akkor írjuk az Azonosítóba kis kezdőbetűvel. A tulajdonságok nevei tartalmazhatnak ékezetes betűket is.
A Schema-ban megnézhetjük a paraméterek részletes adatait:

Megjelenik a paraméterek Azonosítója, Címkéje, a paraméter típusa, integer és number esetén a mérete, korlátos string esetén a maximális hossza, felsorolt típus esetén a használható értékek és jelentésük.
A JSON objektum híváskor a body-ba kerül:
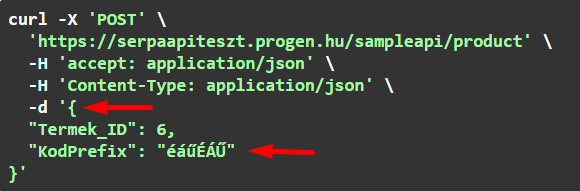
8.4. Body paraméterek "Lekérdezés sERPából" típus, POST metódus és XML adatformátum esetén

Készítsünk példát, próbáljuk ki, mentsük el:
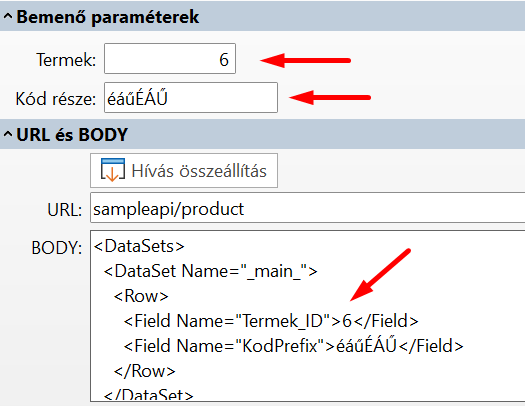
Ha nem készítünk példát, akkor a sERPa API készít egyet, amelynek a felépítése ugyanolyan lesz, mint az általunk készített példának, csak nem lesznek benne értelmes adatok.
A paramétereket egy UTF-8 kódolású XML-ben kell átadni:
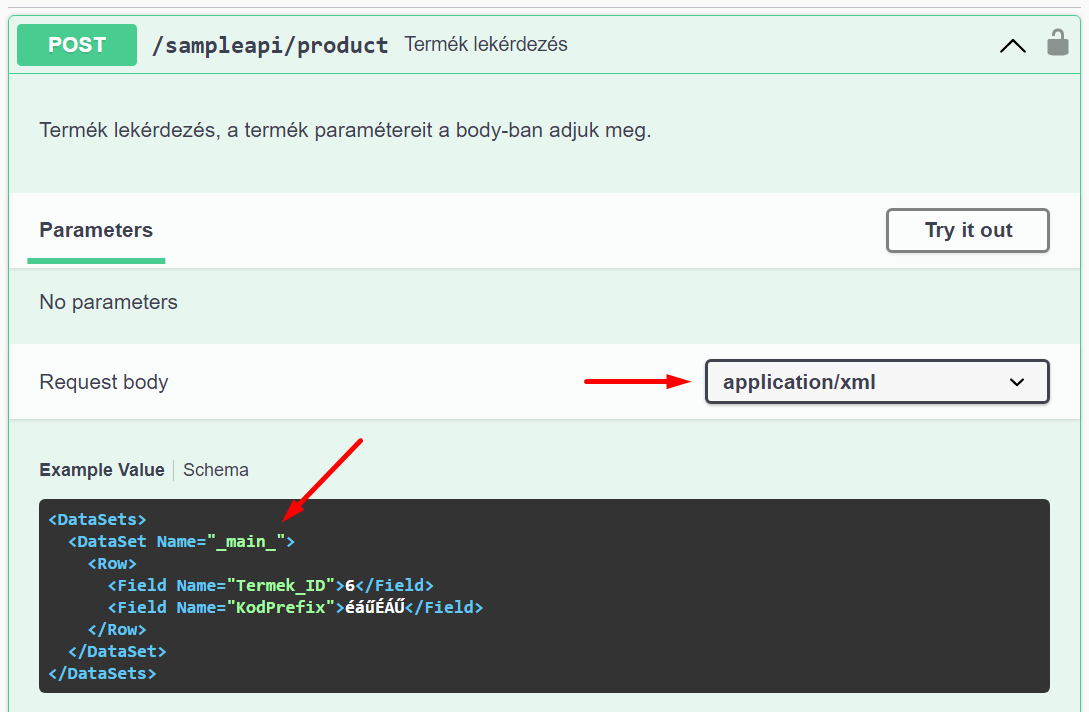
Az XML felépítése kötött, mindig pontosan ilyen formában kell átadni a paramétereket. Értelemszerűen annyi Field elem lesz, ahány paraméterünk van. A Field Name attribútumban van a paraméter neve, a Field elem szövege a paraméter értéke. A Name attribútumok értékei kisbetű-nagybetű híven követik a sERPa Eredményhalmaz-lekérdezés Bemenő Paraméter fülén, az Azonosító oszlopban megadott értékeket, és tartalmazhatnak ékezetes betűket is.
A Schema-ban megnézhetjük a paraméterek részletes adatait:

A Swagger nem támogatja az olyan XML elemeket, amelyeknek egyszerre van attribútuma és szövege, ezért a paraméter tulajdonságokat csak nem szabványos formában, szövegként lehet berakni a paraméter leírásába.
Az XML híváskor a body-ba kerül:
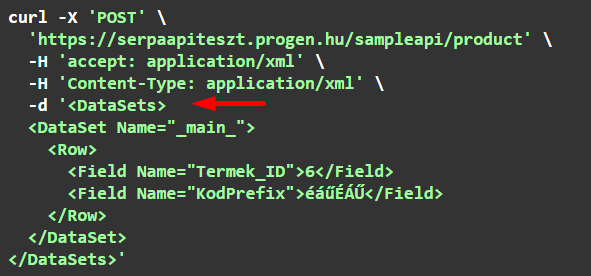
Az XML-ben lehet fejléc:
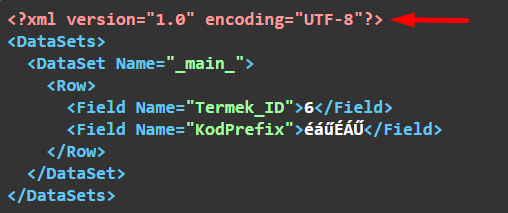
Az XML fejléc csak UTF-8 kódolást írhat elő. Az XML csak UTF-8 kódolású lehet.
8.5. Body paraméterek "Adatátadás sERPának" típus, POST, PUT, PATCH metódusok és JSON adatformátum esetén
A paraméterekben mindig egy tömböt kell átadni, amelyben egy vagy több objektum lehet, így egy hívással egyszerre egy vagy több elemet tudunk felvenni, módosítani.
A tömbben szereplő objektum összetett belső szerkezettel rendelkezhet, lehetnek benne további gyermekobjektumok, tömb, amely szintén összetett belső szerkezettel rendelkező objektumokat tartalmazhat. Az objektumban csak egy tömb lehet, és az nem tartalmazhat további tömböket, tehát csak egy darab, egyszintű fejléc-tétel kapcsolat engedélyezett.
A paraméterek forrása a végponthoz rendelt művelet:
de abban csak a paraméterek egyszerű felsorolása, illetve a táblázat, táblázat elemek jelölése szerepel:
Nincs benne összetett szerkezet.
Másrészt a műveletnek vannak olyan paraméterei, amelyeket fixen meg szeretnénk adni, nem vezetjük ki a végpont paraméterei közé.
Ezért szükség van egy összerendelő táblára, amely megmondja, hogy mely művelet paraméterek legyenek fixek, melyek legyenek végpont paraméterek, és a Művelet lineáris adatszerkezetéből egy összetett, hierarchikus objektumszerkezetet készít.
Ez a tábla az Interfész elemben található.
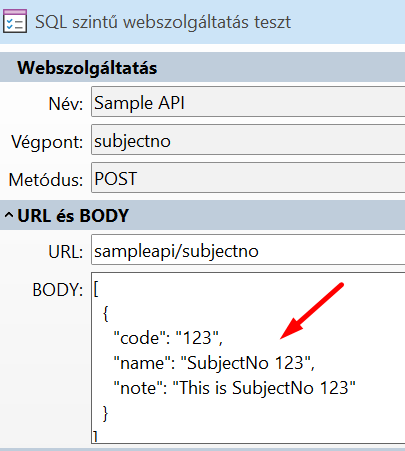
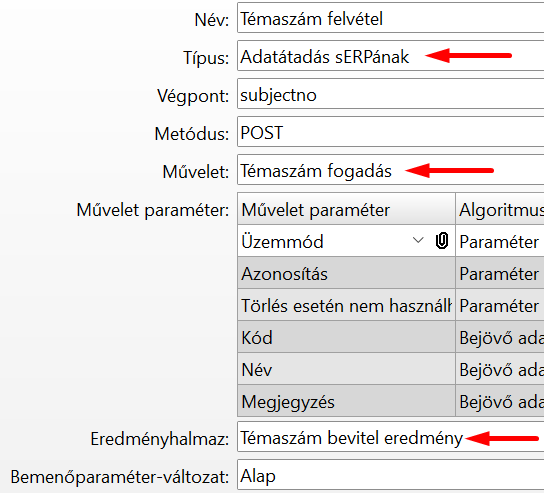
Kezdjük egy egyszerű példával. A Témaszám felvétel végpont a Témaszám fogadás műveletet használja:
A Témaszám fogadás műveletnek viszonylag kevés Bemenő paramétere van, és abból is csak három kötelező:
Az Interfész elem Művelet paraméter táblájában készíthetjük el az összerendelést:
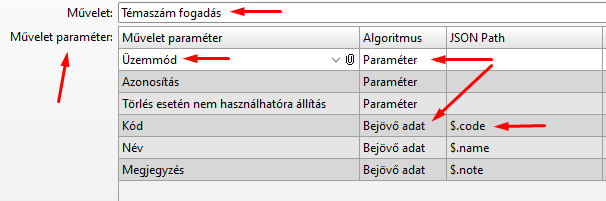
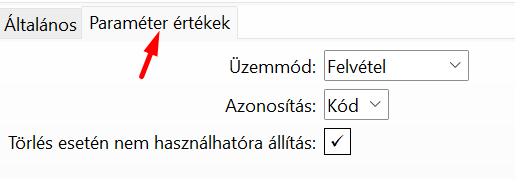
Az "Üzemmód", "Azonosítás" és "Törlés esetén nem használhatóra állítás" mezőket "Paraméter" algoritmusra állítottuk, ez azt jelenti, hogy ezek fix értékkel rendelkeznek, az interfész elem "Paraméter értékek" fülén kell nekik értéket adni:
Ezzel a fix paramétereket el is intéztük.
A többi mező algoritmusa "Bejövő adat", ami azt jelenti, hogy ezek lesznek az API végpont paraméterei.
Csak véletlen egybeesés, hogy ebben a példában a kötelező paraméterek lettek "Paraméter" algoritmusúak, és a nem kötelező paraméterek "Bejövő adat" algoritmusúak. A kötelezőségnek és az algoritmusnak semmi köze egymáshoz, egy kötelező paraméter lehet "Paraméter" és "Bejövő adat" is, és ugyanez igaz a nem kötelező paraméterekre is.
Most már csak azt kell megmondanunk, hogy a művelet mezői milyen néven és hova kerüljenek az API végpont paramétereibe. Erre való a JSON Path mező.
Ebben a példában egy egyszerű objektumot szeretnénk definiálni, abban legyen a három mező, melyeknek kisbetűvel kezdődő angol neve legyen.
A JSON Path mindig "$"-ral kezdődik, ez jelenti a gyökér objektumot. Feljebb azt írtuk, hogy a paraméterek egy tömbbe kerülnek. Ez így van, de ezt a tömböt nem jelöljük a JSON Path-ban, hogy egyszerűbb dolgunk legyen. Tehát a JSON Path-ban csak a tömbben lévő objektum szerkezetét kell leírni. A JSON path elemeit egy-egy "." választja el egymástól. Az utolsó elem lesz a mező neve. Mivel most a gyökér objektum és a mező neve között nincs semmi, ez azt jelenti, hogy mindhárom mező a gyökér objektumba kerül. Az API végpont paramétereinek felépítése a következő lesz:
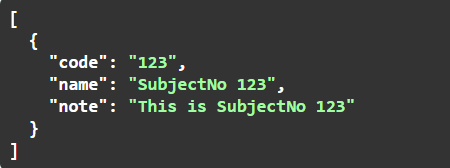
Kívül van egy tömb "[]", abban egy objektum "{}", abban pedig a paraméterek, értékekkel.
Természetesen egyszerre több elemet is átadhatunk a tömbben:
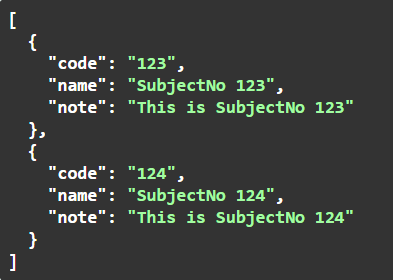
A továbbiakban minden példában csak egy elem lesz a tömbökben, hogy ne legyenek feleslegesen nagyok a képek, de mindig minden tömbben lehet több elem.
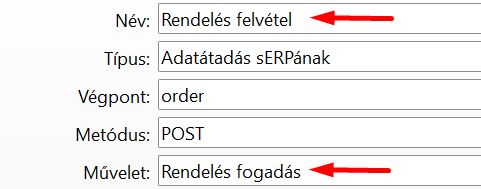
Most nézzünk egy állatorvosi lovat. A Rendelés fogadás műveletnek 25 paramétere van, a rendelés elemei pedig egy táblázatban vannak, a képet lásd feljebb. Ebből csak néhányat szeretnénk az API végpont paramétereiben megkapni, a következő struktúrában:
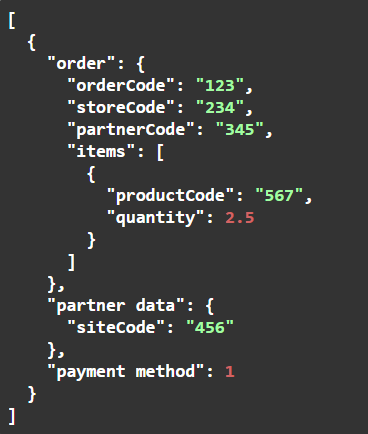
Ez így néz ki az Interfész definícióban:
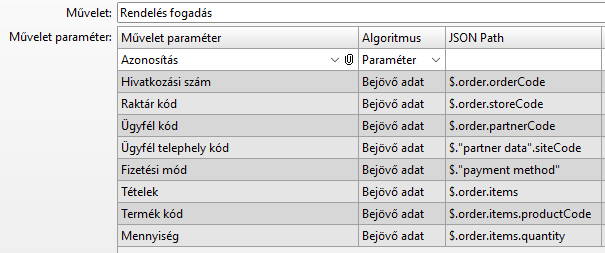
Az első a "Hivatkozási szám" mező. A rendelés adatait egy "order" objektumba szeretnénk csoportosítani, ami a root objektum egy mezője. Ezt a "$.order.orderCode" JSON Path-tal tudjuk jelölni. A "$" jelenti a root objektumot. Mivel az "order" nem az utolsó elem a path-ban, ezért egy gyermekobjektumot jelöl. Az "order" objektum mezője lesz az "orderCode".
A neveket a JSON-ben szokásos "camelCase" szerint neveztük el: kis kezdőbetű, a szavak egybeírva, a többi szó nagybetűvel kezdődik. Ez nem kötelező, de a JSON-ben így szokás.
A "Raktár kód", "Ügyfél kód" mezők ugyanúgy az "order" objektumba kerülnek.
Az "Ügyfél telephely kód" mezőt a root objektumon belül egy másik objektumba szeretnénk rakni, ezt a "$."partner data".siteCode" JSON path-tal adtuk meg. A "partner data" a gyermekobjektum neve. Azért van ""-ök közé rakva, mert szóközt tartalmaz. Ha az objektum- vagy mezőnevek szóközt, vagy bármilyen más, változónévben tiltott karaktert (pl. "$", "-") tartalmaznak, akkor rakjuk ""-ök közé.
Lehetőleg normális változóneveket használjunk: csak az angol ABC kis- és nagybetűi, számok, '_', betűvel kezdődik. Ez biztosan működik mindenhol. Gondoljunk arra, hogy nem tudhatjuk, az API felhasználói milyen programot használnak. Ha "érdekes" változóneveket használunk (pl. ékezetes betűk), az API felhasználói akadályokba ütközhetnek.
A "Fizetési mód" mező a root objektum mezője, hogy legyen ilyen is. Az egyetlen érdekesség benne az, hogy a mezőnév szóközt tartalmaz, ezért ""-ök közé tettük, ahogy azt az előzőekben megtárgyaltuk.
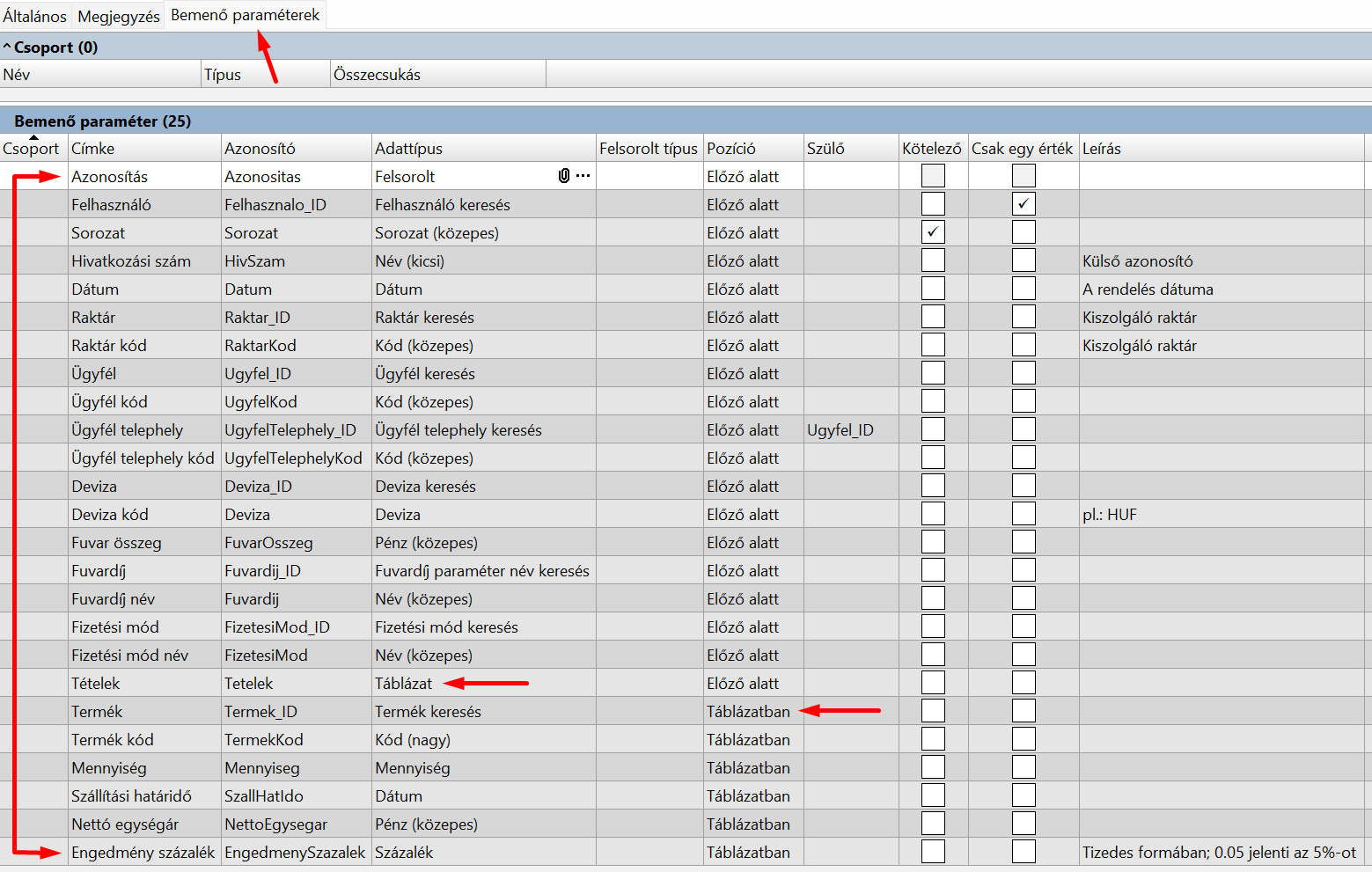
A "Tételek" az "order" objektum "items" nevű mezője lesz. Első ránézésre ennyi. Valójában egy tömb lesz, ami abból derül ki, hogy a Művelet paramétereiben a "Tételek" mező Adattípusa: "Táblázat":

A Művelet paramétereiben a "Termék kód" és "Mennyiség" mezők Pozíciója: "Táblázatban":

és mivel a "Tételek" nevű táblázat alatt vannak, ezért a "Tételek" táblázat elemei.
Ezért a "Termék kód" és "Mennyiség" mezőket nekünk az "items" tömbbe kell rakni.
Ahogy a gyökér tömböt nem jelöltük a JSON Path-ban, "items"-ről sem mondjuk meg, hogy tömb, ezt az imént leírtakból tudjuk, és a sERPa API is tudja. A "productCode" és "quantity" mezők valójában az "items" tömbben található objektumok mezői lesznek.
Itt is készül Schema, minden mezőről megtudható minden lényeges adat:

A sERPa sűrűn használja a 2 bájtos előjeles egész (int16) és az egy bájtos előjel nélküli egész (uint8) típusokat. Az "int16" és "uint8" nem szabványos OpenAPI jelölés, de belekerül a swagger.json-be, hogy lássuk a pontos típust.
A mező leírását három helyen adhatjuk meg.
Az Interfész elemben a Művelet paraméter tábla Leírás mezőjében:

Ha ott nem adtuk meg, akkor a Művelet Bemenő paraméterek tábla Leírás mezője jut érvényre:

Ha ott sem adtuk meg, akkor a Művelet Bemenő paraméterek tábla Címke mezője jut érvényre:

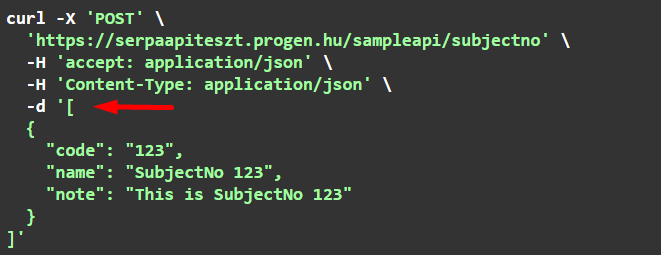
Példát nekünk kell kézzel készíteni, a sERPa nem tudja előállítani:
A JSON tömböt a kérés body-jában kell átadni:
8.6. Body paraméterek "Adatátadás sERPának" típus, POST, PUT, PATCH metódusok és XML adatformátum esetén
Az XML egy gyökérelemmel kezdődik, ezt az XML szabvány írja elő. A gyökérelemben egy fejléc objektumokból álló tömböt (egy vagy több egyforma XML elemet) adhatunk át, így egy hívással egyszerre egy vagy több elemet tudunk felvenni, módosítani.
A fejléc objektum összetett belső szerkezettel rendelkezhet, lehetnek benne további gyermekobjektumok, valamint egy tétel tömb, amely szintén összetett belső szerkezettel rendelkezhet. A fejléc objektumban csak egy tétel tömb lehet, és az nem tartalmazhat további tömböket, tehát csak egy darab, egyszintű fejléc-tétel kapcsolat engedélyezett.
A paraméterek forrása a végponthoz rendelt művelet:
de abban csak a paraméterek egyszerű felsorolása, illetve a táblázat, táblázat elemek jelölése szerepel:
Nincs benne összetett szerkezet.
Másrészt a műveletnek vannak olyan paraméterei, amelyeket fixen meg szeretnénk adni, nem vezetjük ki a végpont paraméterei közé.
Ezért szükség van egy összerendelő táblára, amely megmondja, hogy mely művelet paraméterek legyenek fixek, melyek legyenek végpont paraméterek, és a Művelet lineáris adatszerkezetéből egy összetett, hierarchikus objektumszerkezetet készít.
Ez a tábla az Interfész elemben található.
Kezdjük egy egyszerű példával. A Témaszám felvétel végpont a Témaszám fogadás műveletet használja:
A Témaszám fogadás műveletnek viszonylag kevés Bemenő paramétere van, és abból is csak három kötelező:
Az Interfész elem Művelet paraméter táblájában készíthetjük el az összerendelést:
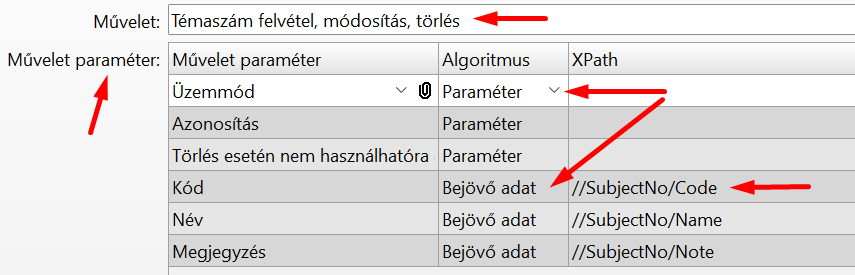
Az "Üzemmód", "Azonosítás" és "Törlés esetén nem használhatóra állítás" mezőket "Paraméter" algoritmusra állítottuk, ez azt jelenti, hogy ezek fix értékkel rendelkeznek, az interfész elem "Paraméter értékek" fülén kell nekik értéket adni:
Ezzel a fix paramétereket el is intéztük.
A többi mező algoritmusa "Bejövő adat", ami azt jelenti, hogy ezek lesznek az API végpont paraméterei.
Csak véletlen egybeesés, hogy ebben a példában a kötelező paraméterek lettek "Paraméter" algoritmusúak, és a nem kötelező paraméterek "Bejövő adat" algoritmusúak. A kötelezőségnek és az algoritmusnak semmi köze egymáshoz, egy kötelező paraméter lehet "Paraméter" és "Bejövő adat" is, és ugyanez igaz a nem kötelező paraméterekre is.
Ebben a példában egy egyszerű objektumot szeretnénk definiálni, abban legyen a három paraméter mező, melyeknek angol neve legyen. Most már csak azt kell megmondanunk, hogy ezek a mezők milyen néven és hova kerüljenek az API végpont paramétereibe. Erre való az XPath.
Az XPath mindig "/" jellel kezdődik, és az elemeket is egy-egy "/" jel választja el egymástól.
Az XPath első eleme a gyökérelem neve. Ha nem adjuk meg (az XPath "//"-rel kezdődik), akkor a gyökérelem neve "root" lesz. A gyökérelem neve minden paraméterben ugyanaz kell, hogy legyen.
Az XPath második eleme a fejléc objektum neve. Ez kötelező. A fejléc objektum neve minden paraméterben ugyanaz kell, hogy legyen.
Az XPath utolsó eleme lesz a mező neve.
A fejléc objektum és a mezőnév között (az XPath második és utolsó eleme között) lehetnek a gyermekobjektumok nevei. Mivel a fenti példában a fejléc objektum és a mezőnév között nincs semmi, ez azt jelenti, hogy mindhárom paraméter a fejléc objektumba kerül.
Az XML elem- és attribútumnevek, így az XPath elemek szabályai:
•A név az angol ABC kis- és nagybetűit, számot, kötőjelet, aláhúzást és pontot tartalmazhat.
•A nevek betűvel vagy aláhúzás karakterrel kell kezdődjenek.
•A név nem kezdődhet "xml"-lel (semmilyen kisbetű-nagybetű kombinációban),
•A nevek kisbetű-nagybetű érzékenyek.
•A név nem tartalmazhat szóközt.
Ezeket a szabályokat nekünk kell betartani.
Az API végpont paramétereinek felépítése a következő lesz:
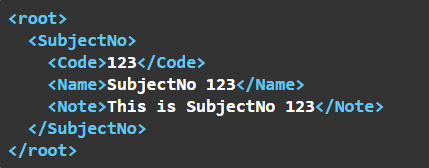
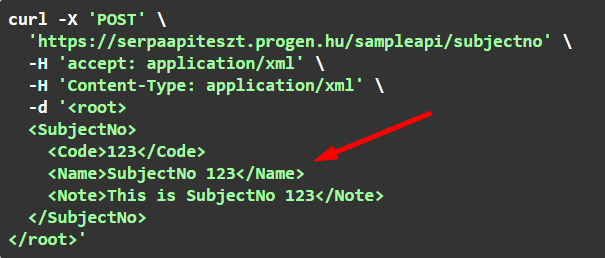
A root egy SubjectNo elemekből álló tömb, így egyszerre több SubjectNo elemet is átadhatunk a tömbben:
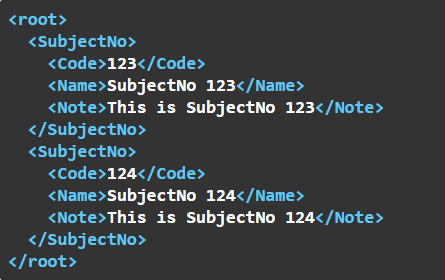
A továbbiakban minden példában csak egy elem lesz a tömbökben, hogy ne legyenek feleslegesen nagyok a képek, de mindig minden tömbben lehet több elem.
Most nézzünk egy állatorvosi lovat. A Rendelés fogadás műveletnek 25 paramétere van, a rendelés elemei pedig egy táblázatban vannak, a képet lásd feljebb. Ebből csak néhányat szeretnénk az API végpont paramétereiben megkapni, a következő struktúrában:
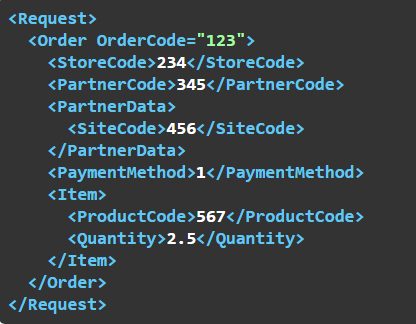
Ez így néz ki az Interfész definícióban:
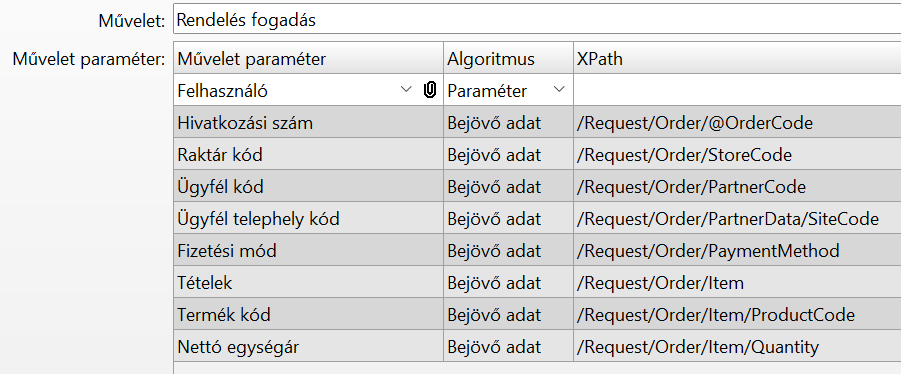
A gyökérelem neve "Request", ezt minden sorban meg kell adnunk.
A fejléc objektum neve "Order", ezt is minden sorban meg kell adnunk.
Az első a "Hivatkozási szám" paraméter, ami nem XML elem, hanem az Order elem attribútuma lesz, ezt a neve elé rakott '@' jellel jelezzük. Az attribútum neve "OrderCode" lesz.
A neveket az XML-ben szokásos "PascalCase" szerint neveztük el: nagy kezdőbetű, a szavak egybeírva, a többi szó nagybetűvel kezdődik. Ez nem kötelező, de az XML-ben így szokás.
A "Raktár kód", "Ügyfél kód" mezők az Order objektumba kerülnek, saját XML elembe.
Az "Ügyfél telephely kód" mezőt az Order objektumon belül egy másik objektumba szeretnénk rakni, ezt a "/Request/Order/PartnerData/SiteCode" XPath-tal adtuk meg. A "PartnerData" a gyermekobjektum neve.
A "Fizetési mód" mező szintén az Order objektum mezője.
A "Tételek" az "Order" objektum "Item" nevű eleme lesz. Első ránézésre ennyi. Valójában egy tömb lesz, ami abból derül ki, hogy a Művelet paramétereiben a "Tételek" mező Adattípusa: "Táblázat":
A Művelet paramétereiben a "Termék kód" és "Mennyiség" mezők Pozíciója: "Táblázatban":
és mivel a "Tételek" nevű táblázat alatt vannak, ezért a "Tételek" táblázat elemei.
Ezért a "Termék kód" és "Mennyiség" mezőket nekünk az "Item" tömbbe kell rakni.
Ahogy az Order tömböt nem jelöltük az XPath-ban, "Item"-ről sem mondjuk meg, hogy tömb, ezt az imént leírtakból tudjuk, és a sERPa API is tudja. A "ProductCode" és "Quantity" mezők valójában az "Item" tömbben található objektumok mezői lesznek.
Itt is készül Schema, minden mezőről megtudható minden lényeges adat:

Látjuk, hogy Order és Item tömb.
Az XML Attribútumok esetén az attribútum tulajdonságai (típusa, mérete, stb.) az attribútum leírásába kerülnek.
A sERPa sűrűn használja a 2 bájtos előjeles egész (int16) és az egy bájtos előjel nélküli egész (uint8) típusokat. Az "int16" és "uint8" nem szabványos OpenAPI jelölés, de belekerül a swagger.json-be, hogy lássuk a pontos típust.
A mező leírását három helyen adhatjuk meg.
Az Interfész elemben a Művelet paraméter tábla Leírás mezőjében:

Ha ott nem adtuk meg, akkor a Művelet Bemenő paraméterek tábla Leírás mezője jut érvényre:
Ha ott sem adtuk meg, akkor a Művelet Bemenő paraméterek tábla Címke mezője jut érvényre:
Példát nekünk kell kézzel készíteni, a sERPa nem tudja előállítani:
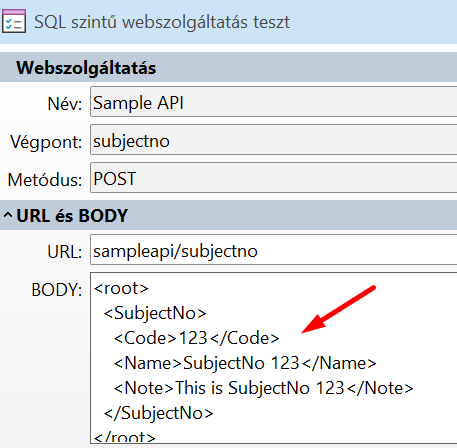
Ha nem adunk meg példát, a sERPaAPI készít egyet, de abban nem lesznek értelmes adatok.
Az XML-t a kérés body-jában kell átadni:
8.7. Path paraméterek "Adatátadás sERPának" típus és DELETE metódus esetén
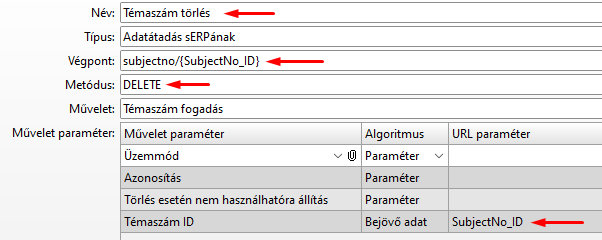
Az Interfész elemben található Művelet paraméter tábla URL paraméter oszlopában adjuk meg a "Bejövő adat" algoritmusú paraméterek nevét. Ezt a nevet használjuk a Végpont-ban, a GET metódusnál leírtaknak megfelelően:
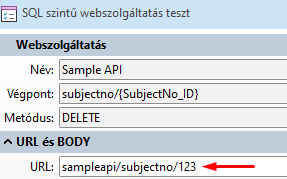
Példát nekünk kell kézzel készíteni:
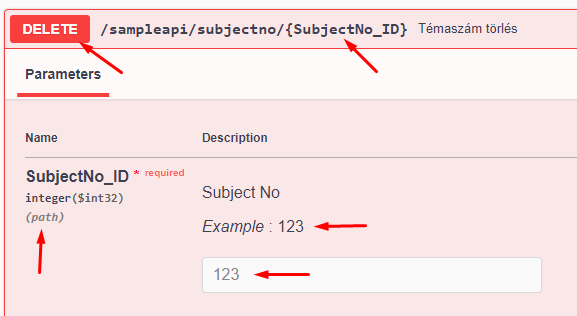
Így jelenik meg a Swagger-ben:
A mező leírását a POST, PUT, PATCH metódusoknál leírtak szerint adhatjuk meg.
9. Eredmény
A sERPa API csak a 200 OK válaszhoz készít leírást a swagger.json fájlba. Egyéb válaszokat is kaphatunk az API-tól, pl. 400 Bad Request, 401 Unauthorized, 500 Internal Server Error. Ezekről nincs leírás a swagger.json fájlban, de az API hívójának ezeket is kezelni kell.
A sERPa API az Interfész definícióban megadott eredményhalmaz-lekérdezés eredményét adja vissza.
"Lekérdezés sERPából" esetén egyszerűen lefut az eredményhalmaz-lekérdezés, és az adatbázis aktuális állapota alapján megkapjuk az eredményt:

"Adatátadás sERPának" esetén először lefut a Művelet, ez hajtja végre a változtatásokat az adatbázisban, majd utána lefut az eredményhalmaz-lekérdezés, ami már az adatbázis megváltozott állapota alapján adja vissza az eredményt, látjuk a változásokat:
Ebből következően "Lekérdezés sERPából" típusú API végpont készítéséhez nincs szükség programozásra, csak az eredményhalmaz-lekérdezést és az interfészt kell konfigurálni. Ezt a tanácsadó, vagy akár az ügyfél is el tudja végezni. "Adatátadás sERPának" típusú API végponthoz készíteni kell egy Műveletet, ami programozói feladat, mivel ez az adatbázis megváltoztatásával jár.
9.1. JSON eredmény felépítése
Az eredményhalmaz felépítésének függvényében háromféle JSON eredményünk lehet:
1.Van olyan eredménytáblázat, amelyben van értéke a "Tábla név 2" mezőnek: adatszerkezet: objektum – tömb – objektum.
2.Több eredménytáblázat van, és egyikben sincs értéke a "Tábla név 2" mezőnek: adatszerkezet: tömb – tömb – objektum.
3.Egy eredménytáblázat van, és nincs értéke a "Tábla név 2" mezőnek: adatszerkezet: tömb – objektum.
Nézzünk mindháromra példát.
Van olyan eredménytáblázat, amelyben van értéke a "Tábla név 2" mezőnek
Interfész:

Az eredményhalmaz-lekérdezés:
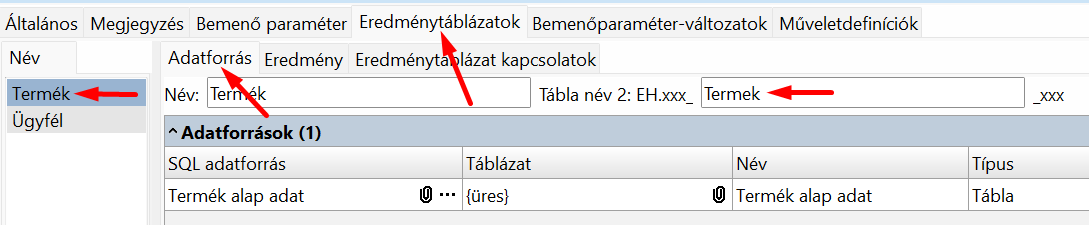
Első tábla, van "Tábla név 2":
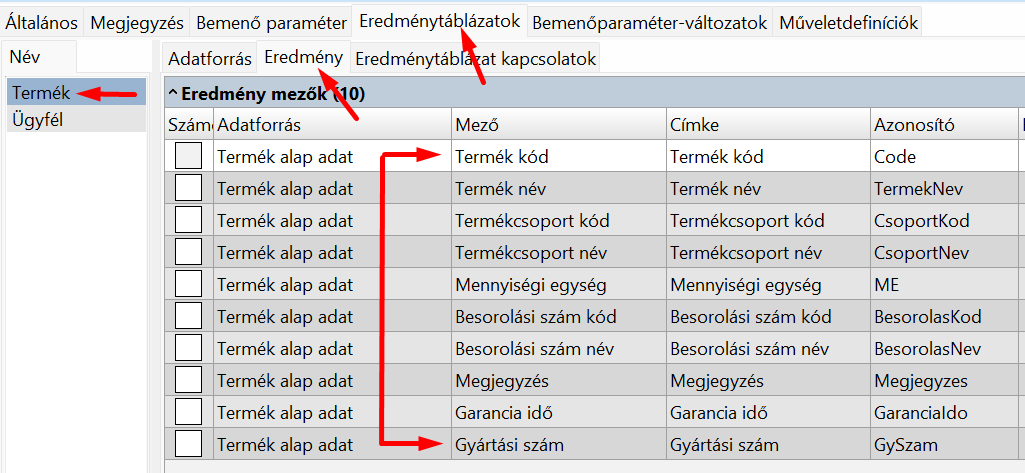
Az első tábla mezői, ezek kerülnek az eredmény első tömbjébe:
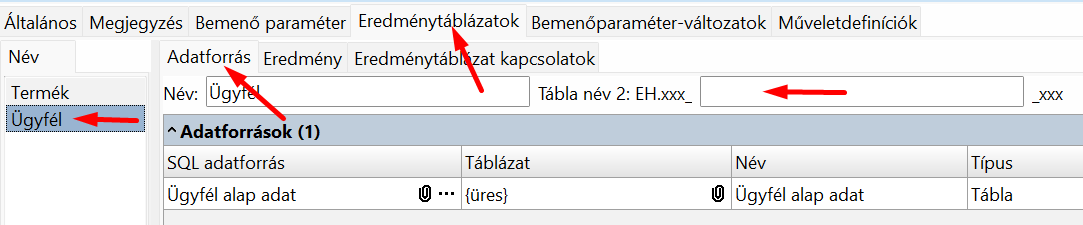
Második tábla, nincs "Tábla név 2":
A második tábla mezői, ezek kerülnek az eredmény második tömbjébe:
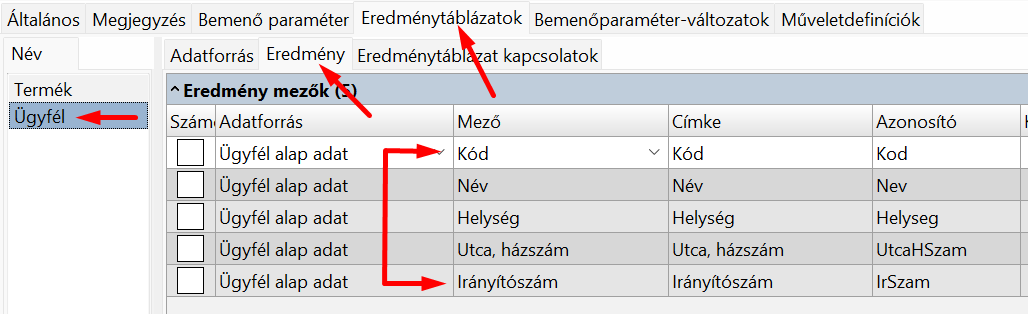
Két eredménytáblázatunk van (Termék és Ügyfél), és legalább az az egyiknek van neve (a Termék eredménytáblázatnak Termek), a másiknak (Ügyfél) nincs.
Az eredmény szerkezete:
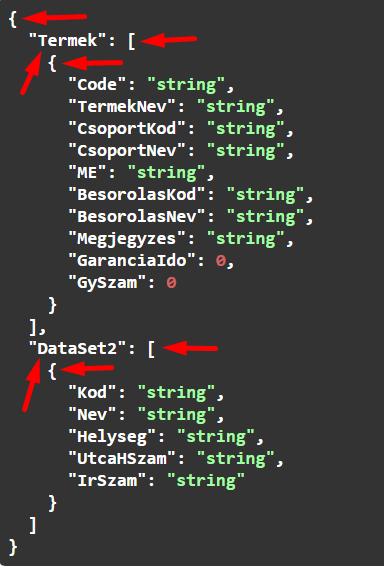
Láthatjuk, hogy a root elem egy objektum, abban van két mező a két táblának, Mivel az Ügyfél eredménytáblázatnak nem adtunk nevet, a sERPa API adott neki automatikusan egyet: "DataSet" + a tábla sorszáma. Mindkét tábla objektumai az eredményhalmaz-lekérdezés eredménytáblázatában lévő mezőket tartalmazzák, az Azonosító lesz a mezőnév.
Ha az Ügyfél eredménytáblázatban is van "Tábla név 2":

Természetesen az eredményben is lesz neve:
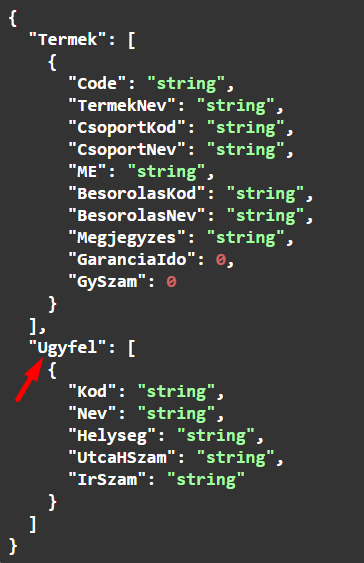
Több eredménytáblázat van, és egyikben sincs értéke a "Tábla név 2" mezőnek


Az eredmény szerkezete:
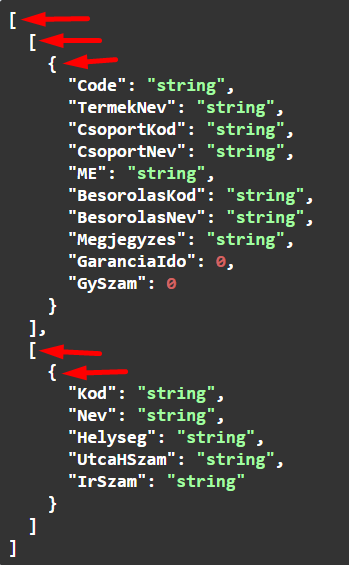
A root elem eddig egy objektum volt, most meg egy tömb. Nem tűnik nagy változásnak. Valójában teljesen megváltozott az eredmény szerkezete, ez egy breaking change, ennek a változtatásnak a hatására növelni kell a főverziószámot, vagy egy teljesen új hívást, egy teljesen új API-t kell készíteni. A tanulság ebből az, hogy egy olyan, teljesen ártalmatlannak tűnő változtatás, mint az, hogy nevet adunk az eredményhalmaz eredménytáblázatának, vagy töröljük a nevét, olyan mélyreható változásokat okoz az API-ban, amitől az API eddigi felhasználói számára használhatatlan lesz, nekik is át kell írniuk a programjukat.
Az API publikálása után ne változtassunk az API-n, sem a mögötte álló eredményhalmaz-lekérdezéseken, műveleteken, vagy ha mégis, alaposan gondoljuk át a változtatásokat, teszteljük, milyen hatása lesz.
Egy eredménytáblázat van, és nincs értéke a "Tábla név 2" mezőnek

Az eredmény szerkezete:
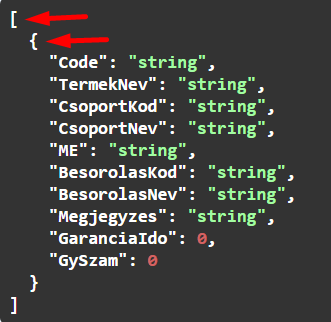
Az eredmény egy tömb lesz, és közvetlenül abban lesznek az eredmény tábla elemei.
JSON Schema
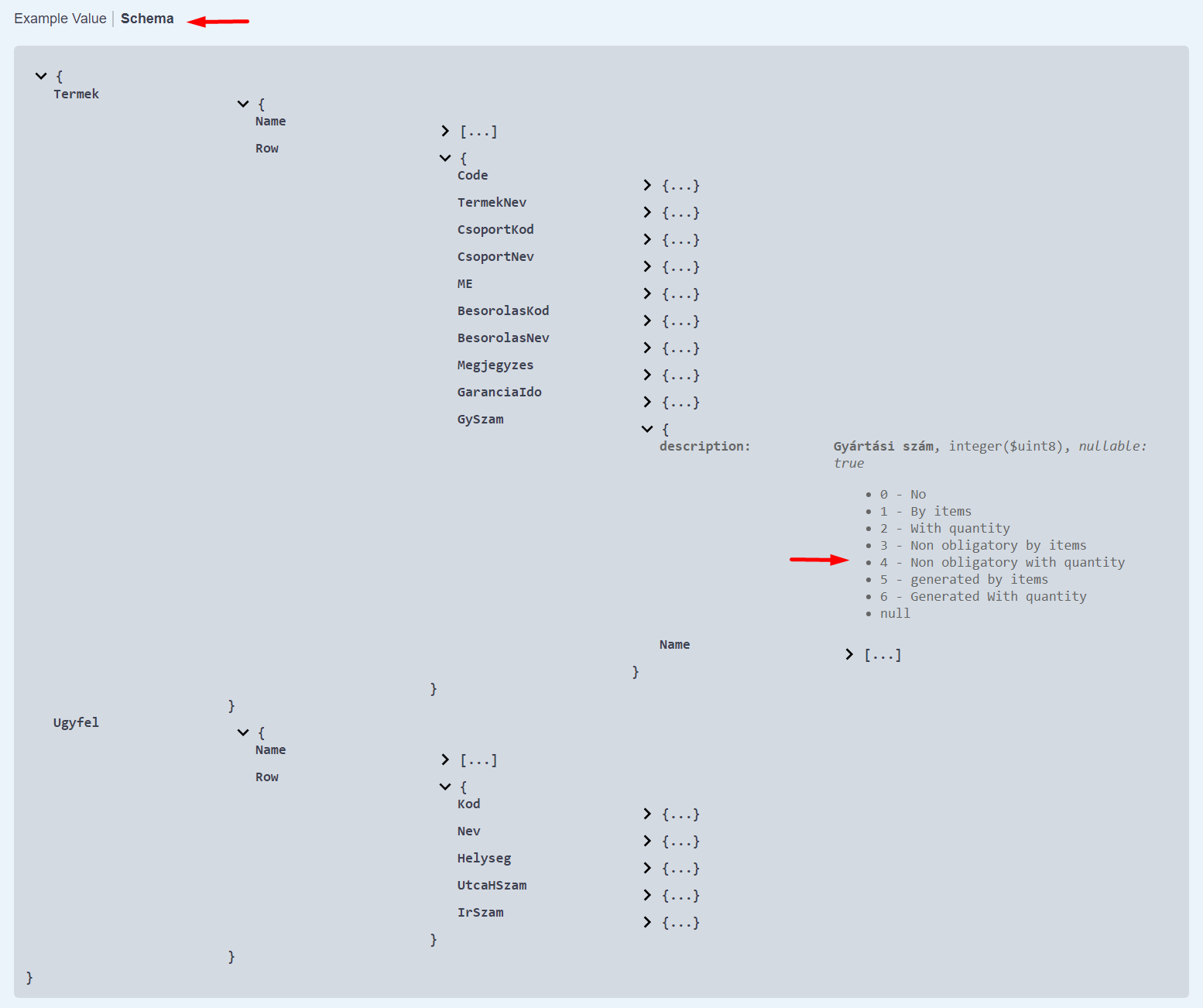
A JSON eredményhez is készül Schema. Az alábbi Schema az 1/b esethez tartozik (két tábla, mindkettőnek van neve):
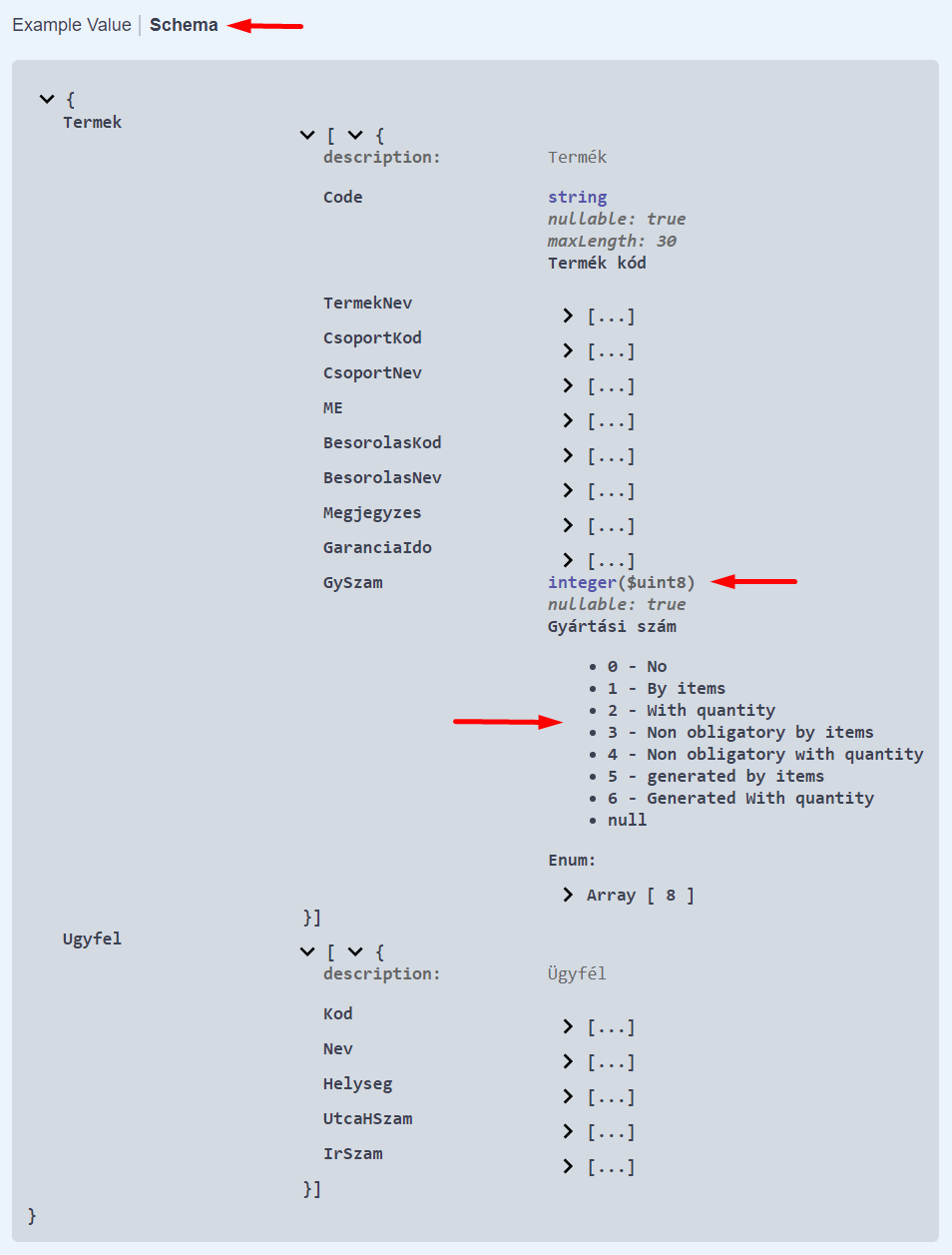
A fenti példában a GySzam egy felsorolt típus, előjel nélküli egy bájtos egész típusú, láthatjuk az összes lehetséges értéket.
9.2. XML eredmény felépítése
Az eredményhalmaz felépítésének függvényében kétféle XML eredményünk lehet:
1.Van olyan eredménytáblázat, amelyben van értéke a "Tábla név 2" mezőnek: mindegyik DataSet-nek lesz Name attribútuma
2.Egyik eredménytáblázatban sincs értéke a "Tábla név 2" mezőnek: egyik DataSet-nek sen lesz Name attribútuma
Nézzünk mindkettőre példát.
Van olyan eredménytáblázat, amelyben van értéke a "Tábla név 2" mezőnek
Az eredményhalmaz-lekérdezés:
Első tábla, van "Tábla név 2":
Második tábla, nincs "Tábla név 2":
Két eredménytáblázatunk van (Termék és Ügyfél), és legalább az az egyiknek van neve (a Termék eredménytáblázatnak Termek), a másiknak (Ügyfél) nincs.
Az eredmény szerkezete:
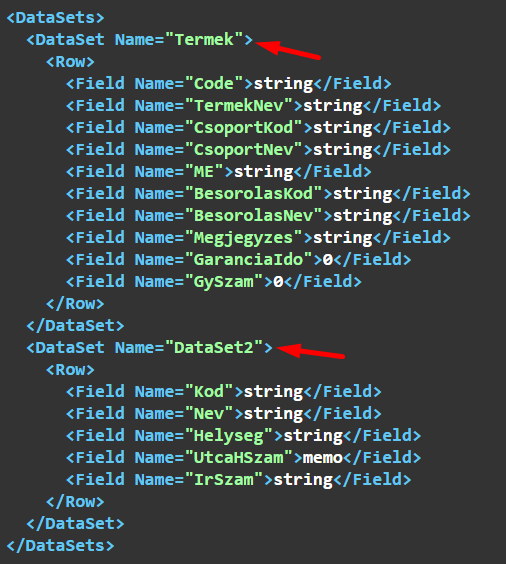
Mindegyik DataSet-nek lesz neve. Amelyiknek nem adtunk nevet, annak "DataSet" + a tábla sorszáma lesz a neve.
Egyik eredménytáblázatban sincs értéke a "Tábla név 2" mezőnek
Az eredményhalmaz:
Az eredmény szerkezete:
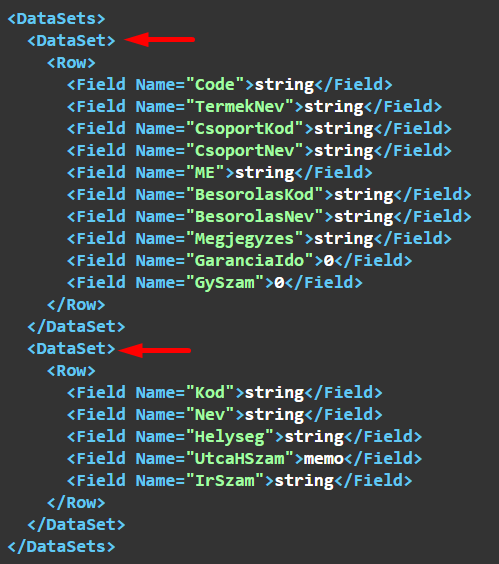
Teljesen elenyészőnek látszik a különbség, de valójában az első esetben DataSets egy objektum, a második esetben pedig egy tömb.
XML Schema
Az XML eredményhez is készül Schema.
A Swagger nem támogatja az olyan XML elemeket, amelyeknek egyszerre van attribútuma és szövege, ezért a paraméter tulajdonságokat csak nem szabványos formában, szövegként lehet berakni a paraméter leírásába.